[TIL] 사용자 흐름에 맞춰 ERD 다듬기
TodayPoor ERD 구조 수정, 사용자 흐름 맞춤 데이터 책임 분리 및 AI/OCR 결과 관리 방식
For the English version of this post, see here.
오늘 한 일
- 최종 기획서 작성
운영진 피드백 반영
피드백에 대한 우리 팀의 생각 반영
- ERD 수정사항 정리
피드백 반영
와이어프레임과 비교
- ERD 수정사항 반영
ERD 수정
TodayPoor 프로젝트의 1차 기획 피드백을 바탕으로 서비스 방향성과 ERD 구조를 다시 정리함
1차 수정
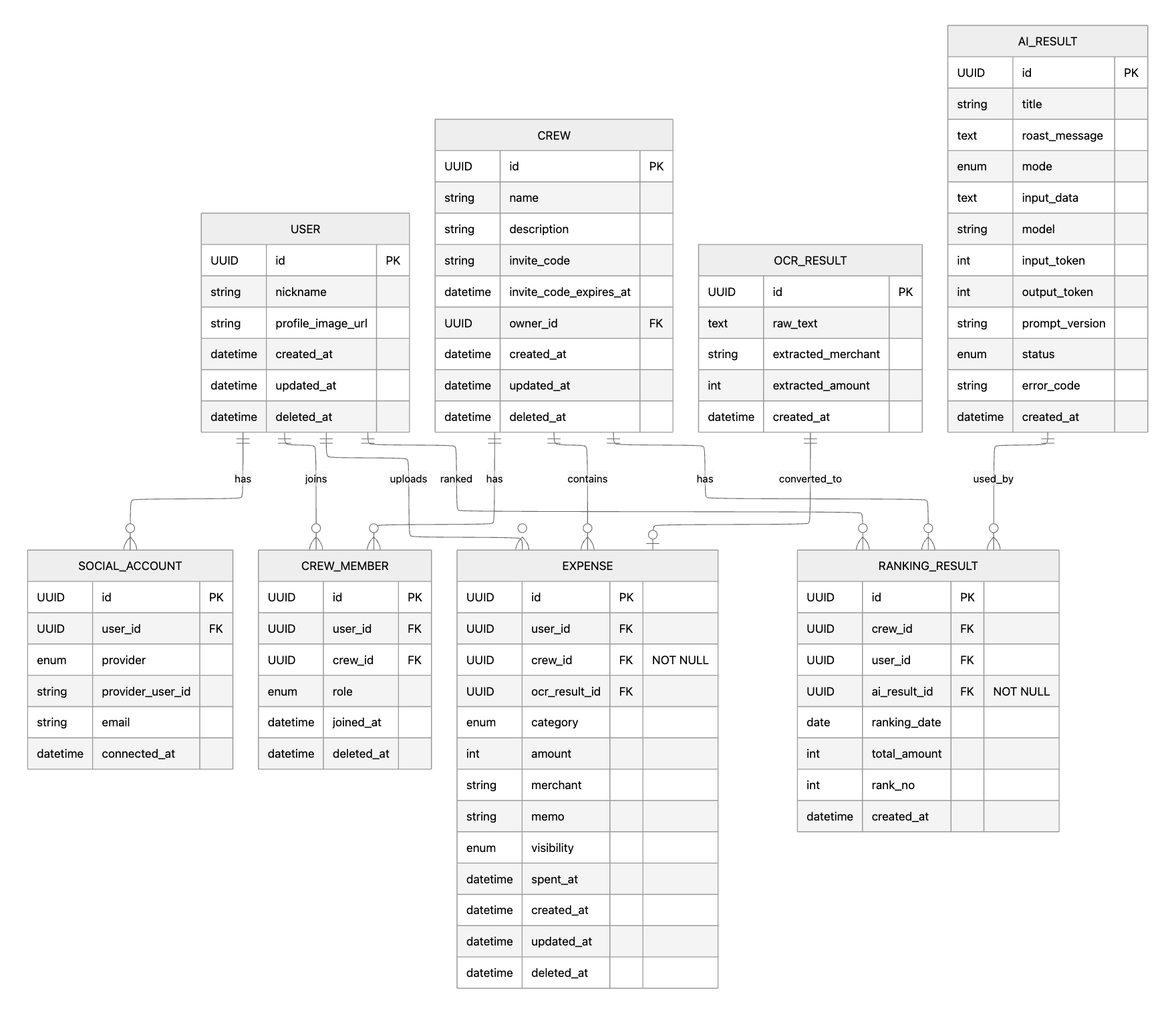
변경 항목 기존 구조 변경 구조 변경 이유 그룹 용어 변경 GROUP, GROUP_MEMBER CREW, CREW_MEMBER 프론트 와이어프레임에서 “크루”라는 용어를 사용하므로 FE/BE/기획서 용어를 통일하기 위해 변경 그룹 FK명 변경 group_id crew_id 테이블명이 CREW로 변경되었기 때문에 FK명도 일관성 있게 수정 크루 설명 추가 없음 CREW.description 추가 와이어프레임의 크루 카드에 설명 문구가 필요하므로 크루 소개/설명 정보를 저장하기 위해 추가 POOR_TITLE 제거 POOR_TITLE 테이블 존재 테이블 삭제 타이틀을 고정값으로 관리하지 않고 AI가 매번 생성하는 방식으로 변경했기 때문에 별도 타이틀 테이블이 불필요해짐 AI 결과 필드 추가 AI_RESULT.output_text 중심 title, roast_message, mode 추가 AI가 수상 타이틀과 독설/피드백 문구를 함께 생성하므로 결과를 구분해 저장하기 위해 추가 AI 모델명 필드명 변경 model_name model 필드명을 더 간결하게 만들기 위해 변경 토큰 사용량 분리 token_usage input_token, output_token 입력 토큰과 출력 토큰을 분리해 AI 사용량을 더 정확히 기록하기 위해 변경 프롬프트 버전 추가 없음 prompt_version 추가 프롬프트를 코드에서 관리하더라도 어떤 버전의 프롬프트로 생성된 결과인지 추적하기 위해 추가 AI 호출 상태 추가 없음 status 추가 AI 호출 성공/실패 여부를 저장하기 위해 추가 AI 에러 코드 추가 없음 error_code 추가 AI 호출 실패 시 원인을 추적하고 디버깅하기 위해 추가 OCR 관계 변경 OCR_RESULT.expense_id EXPENSE.ocr_result_id OCR 결과는 먼저 생성되고, 사용자가 수정/확정한 최종 소비 데이터가 EXPENSE에 저장되므로 EXPENSE가 OCR 결과를 참조하도록 변경 OCR 추출값 추가 OCR_RESULT.raw_text만 저장 extracted_merchant, extracted_amount 추가 OCR이 최초 인식한 가맹점/금액과 사용자가 수정한 최종 값을 비교할 수 있도록 추가 이미지 URL 제거 EXPENSE.image_url 삭제 OCR 인식 후 원본 이미지는 더 이상 필요하지 않으므로 DB에 저장하지 않기 위해 제거 소비-크루 관계 필수화 crew_id nullable 가능 EXPENSE.crew_id NOT NULL 사용자는 반드시 크루에 가입한 상태에서 소비 기록을 등록하도록 정책을 정했기 때문에 필수값으로 설정 랭킹-AI 결과 관계 필수화 ai_result_id nullable 가능 RANKING_RESULT.ai_result_id NOT NULL 크루원들의 MVP 순위는 AI 결과를 필수로 포함하기 때문에 NOT NULL로 설정 랭킹 주기 명확화 ranking_date만 존재 ranking_date를 일간 기준으로 사용 서비스가 하루 단위 MVP/랭킹을 제공하므로 랭킹 날짜를 일간 기준으로 관리 이번 ERD 수정에서는 프론트 와이어프레임 용어와 백엔드 도메인명을 맞추고, AI가 타이틀과 피드백을 생성하는 구조에 맞춰
POOR_TITLE을 제거함또한 OCR 최초 인식 결과와 사용자가 수정한 최종 소비 데이터를 분리하기 위해
OCR_RESULT와EXPENSE의 관계를 재정리함이를 통해 MVP 서비스 흐름에 더 적합한 데이터 구조로 개선함
2차 수정
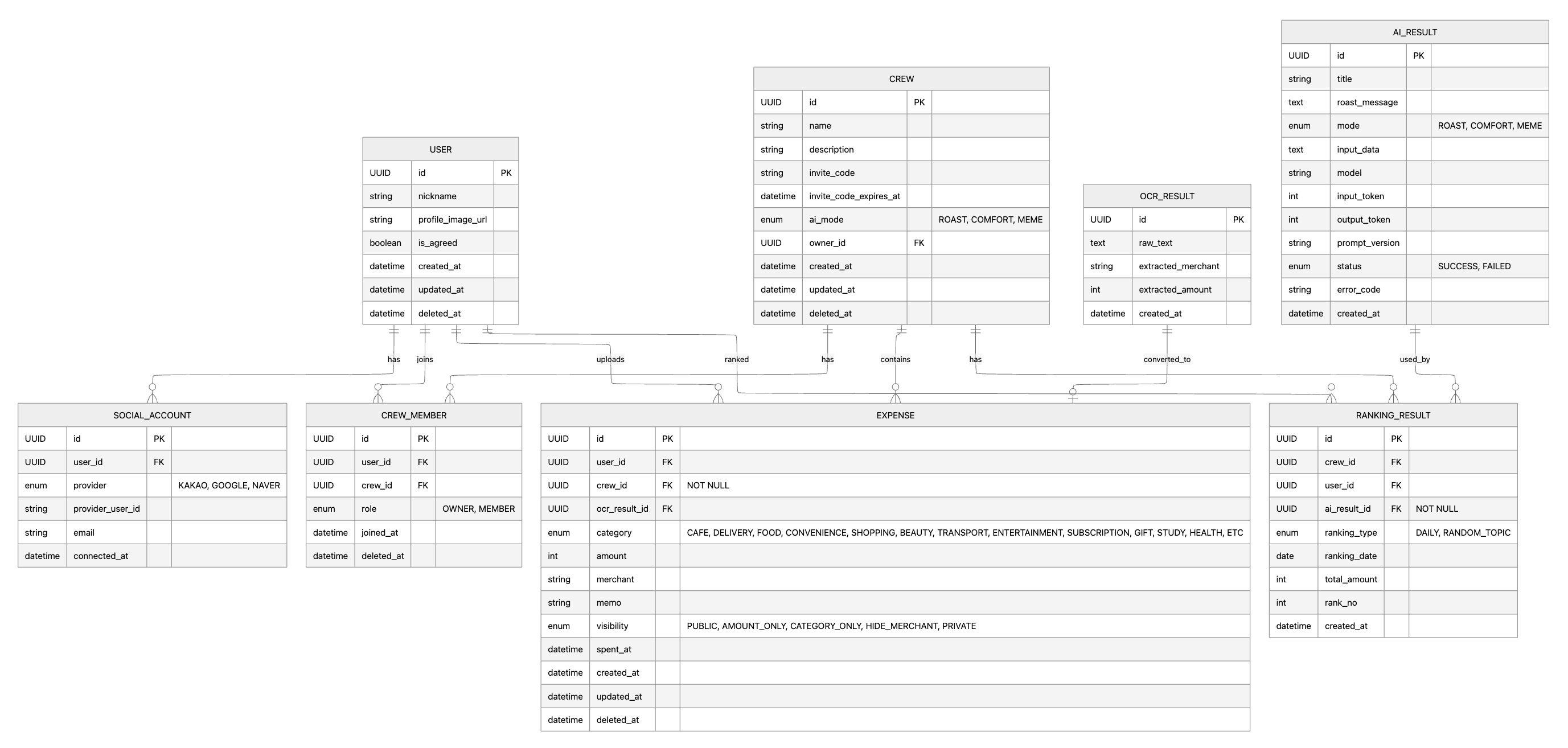
변경 항목 기존 구조 변경 구조 변경 이유 랭킹 유형 추가 RANKING_RESULT에 랭킹 종류 구분 없음 ranking_type 추가 날짜별 랭킹 결과와 랜덤 주제 기반 랭킹 결과를 구분하기 위해 추가 랭킹 타입 enum 정의 없음 DAILY, RANDOM_TOPIC 프론트 와이어프레임에서 일간 결과와 랜덤 주제 결과를 모두 보여주므로 결과 유형을 명확히 구분 회원 정보 동의 여부 추가 USER에 동의 여부 없음 is_agreed 추가 회원가입 시 개인정보 및 서비스 이용 관련 동의 여부를 저장하기 위해 추가 크루별 AI 모드 추가 AI 모드가 결과 테이블에만 존재 CREW.ai_mode 추가 크루마다 AI 피드백 분위기/강도를 설정할 수 있도록 하기 위해 추가 AI 결과 모드 유지 AI_RESULT.mode 존재 그대로 유지 AI 결과가 어떤 모드로 생성되었는지 이력으로 남기기 위해 유지 enum 값 명시 enum provider, enum visibility처럼 타입만 표시 enum 후보값을 Mermaid에 문자열로 명시 ERD만 봐도 어떤 enum 값이 사용되는지 이해할 수 있도록 하기 위해 추가 - 추가로
- 처음에는 크루(CREW) 단에서 AI 모드를 설정하니까, AI_RESULT도 CREW의 ai_mode를 FK처럼 참조해야 하는 거 아닌지 고민함
하지만, 두 값의 역할이 달랐음
CREW.ai_mode는 ‘현재 크루에서 설정해둔 AI 모드 값’이고,
AI_RESULT.mode는 ‘해당 AI 결과가 생성될 당시 실제 사용된 모드 값’임
→ 즉, 크루의 ai_mode는 이후에 변경될 수 있지만, 이미 생성된 AI 결과는 생성 당시 어떤 모드로 만들어졌는지 그대로 유지되어야 함
- 따라서 AI_RESULT가 CREW.ai_mode를 직접 참조(FK)하기보다는, AI 결과 생성 시 사용된 mode 값을 AI_RESULT에 그대로 저장하는 방식이 더 적절하다고 판단함
- 처음에는 크루(CREW) 단에서 AI 모드를 설정하니까, AI_RESULT도 CREW의 ai_mode를 FK처럼 참조해야 하는 거 아닌지 고민함
- 추가로
배운 점
단순히 테이블만 그리는 것이 아니라, 실제 사용자 흐름, FE 화면 구조, 데이터 책임, AI 결과 관리, 운영 및 디버깅, 미래 확장 가능성까지 함께 고려해야 제대로 된 ERD가 나온다는 걸 알 수 있었다.
처음에는 테이블을 많이 만들수록 좋아 보였지만, 오히려 데이터의 책임과 흐름이 명확한 구조가 더 중요하다는 걸 느꼈다.
오늘 논의한 내용들을 바탕으로 앞으로는 API 설계와 실제 서비스 흐름까지 연결해서 고민해봐야겠다.
댓글
궁금한 점, 피드백, 오류 제보를 남겨 주세요.