[TIL] Redis 실전 마스터 클래스 특강 1 - 코어 아키텍처와 캐싱 전략
Redis In-Memory 구조 및 싱글 스레드 아키텍처, 캐싱 전략, 분산 락을 통한 트래픽 처리 및 동시성 문제 해결
For the English version of this post, see here.
배운 내용
Redis 코어 아키텍처와 기초
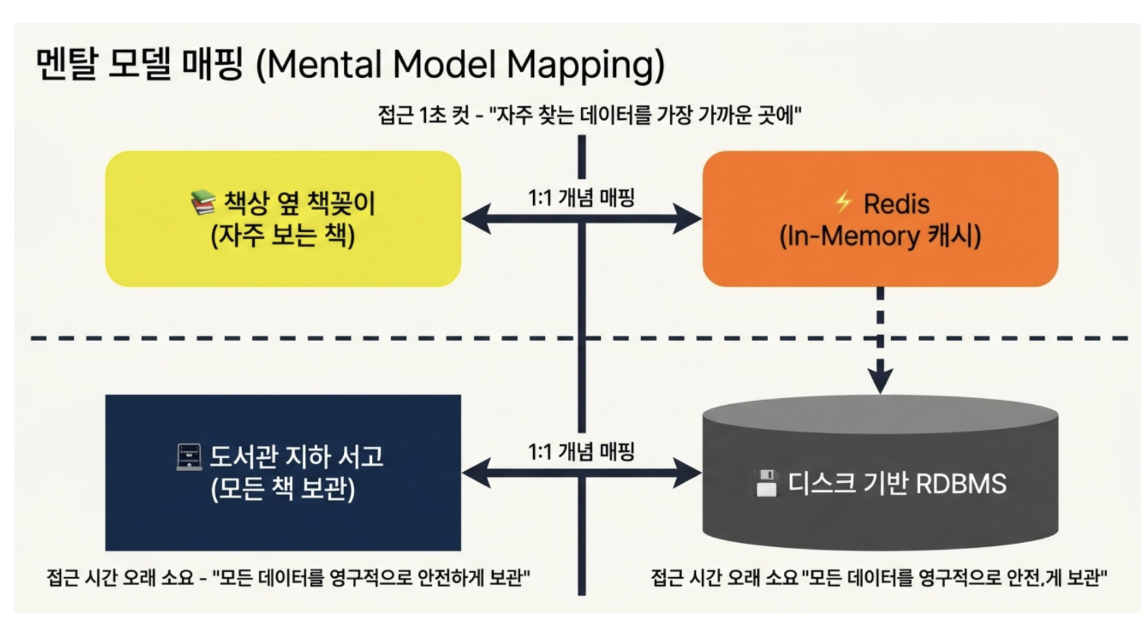
기존의 디스크 기반 DB는 도서과 지하 서고까지 직접 걸어 내려가서 무거운 책을 찾아 꺼내오는 것과 같았다면,
Redis는 자주 보는 책을 책상 옆에 작은 책꽂이에 두고 1초 만에 꺼내 보는 것과 같음
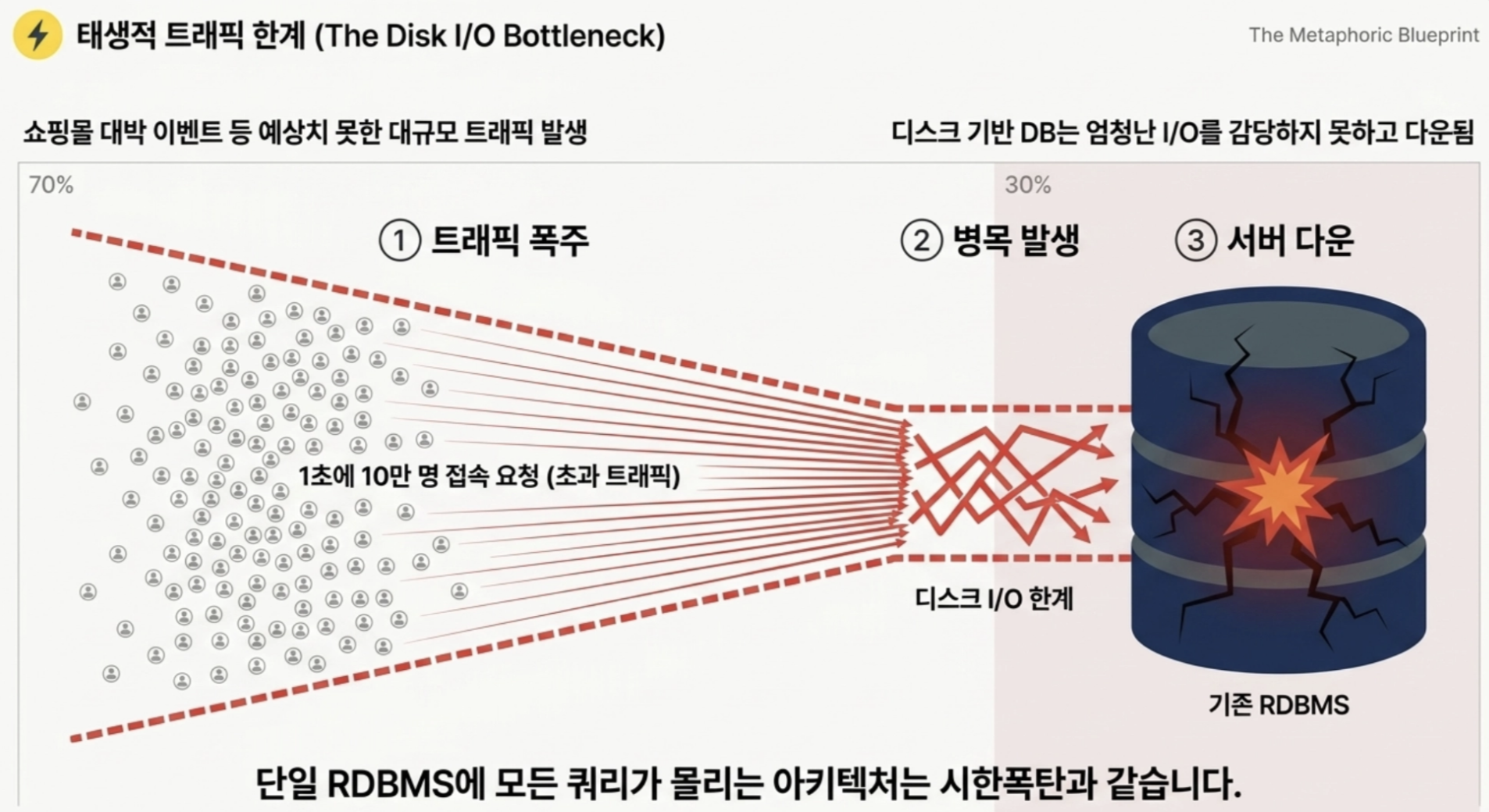
Q 쇼핑몰이 대박 나서 1초에 10만 명의 고객이 메인 페이지에 접속한다면, 기존의 DBMS만 사용한다면 서버는 어떻게 될까?
DB에 쿼리가 너무 많이 몰려서 서버가 다운됨
디스크 기반의 DBMS는 태생적으로 엄청난 트래픽(I/O)를 감당하기 힘듦
→ 서버가 터지는 것을 막고 쇾적한 서비스를 제공하기 위해, 빠르고 안정적인 캐시 시스템인 Redis가 백엔드 아키텍처에서 필수가 됨
1
Redis란 무엇인가 & 경쟁 기술 비교
- Redis
- REmote Dictionary Server의 약자
- REmote (원격의): 우리 애플리케이션 프로그램 내부가 아닌 원격(외부) 프로세스로 존재한다는 뜻
- Dictionary (사전): 파이썬의 딕셔너리나 자바의 HashMap처럼, Key와 Value가 한 쌍으로 이루어진 데이터 구조
- 왜 In-Memory는 디스크보다 압도적으로 빠를까? (물리적 차이)
- RAM(메모리)은 순수하게 논리 회로를 통해 전자의 이동만으로 데이터를 읽고 씀
- 이 물리적 차이로 인해, 메모리 접근 속도가 디스크보다 최소 400배에서 1,000배 이상 빠름
- 눈을 한 번 깜빡이기도 전에 Redis는 이미 수십만 번의 데이터를 넣고 뺄 수 있는 물리적 체급을 갖춤
- RAM(메모리)은 순수하게 논리 회로를 통해 전자의 이동만으로 데이터를 읽고 씀
- Redis가 Memcached를 압도한 이유
- 쇼핑몰에서 ‘실시간 구매왕 랭킹 보드’를 만든다고 할 때,
- Memcached를 사용하면 랭킹 데이터 전체(문자열)를 DB나 Memcached에서 애플리케이션 메모리로 다 가져온 뒤, 애플리케이션 단에서 정렬(Sort)하고 다시 Memcached에 밀어 넣어야 함
- 이 과정에서 다른 유저가 점수를 업데이트하면 데이터 정합성이 깨짐 (Race Condition)
- Redis를 사용하면 내부의 Sorted Set(ZSET) 자료구조를 이용해
ZADD명령어 하나만 날리면, Redis가 메모리 위에서 자체적으로 1초에 수만 건씩 완벽하게 정렬을 유지해줌- 개발의 난이도와 성능 면에서 아예 차원이 달라짐
- Memcached를 사용하면 랭킹 데이터 전체(문자열)를 DB나 Memcached에서 애플리케이션 메모리로 다 가져온 뒤, 애플리케이션 단에서 정렬(Sort)하고 다시 Memcached에 밀어 넣어야 함
- 쇼핑몰에서 ‘실시간 구매왕 랭킹 보드’를 만든다고 할 때,
경쟁 비술 비교 표
비교 항목 Redis Memcached RDBMS (캐시 용도) 로컬 캐시 (Ehcache 등) 속도 매우 빠름 (In-Memory) 매우 빠름 (In-Memory) 느림 (Disk I/O) 가장 빠름 (네트워크 I/O 없음) 자료구조 지원 5종 이상의 풍부한 컴렉션 String (Key-Value) 뿐 테이블, 뷰 등 객체(Object) 자체 저장 데이터 영속성 지원 (RDB 스냅샷, AOF) 미지원 (서버 꺼지면 증발) 완벽 지원 (ACID) 미지원 (서버 꺼지면 증발) 분산 환경 지원 클러스터링, 복제, Sentinel 서드파티 의존 복제 지원 (무거움) 미지원 대표 사용 시나리오 랭킹, 대기열, 세션, 글로벌 캐시 단순 텍스트/세션 캐싱 영구 보존이 필요한 데이터 단일 서버의 설정값, 정적 데이터
싱글 스레드 아키텍처 심화
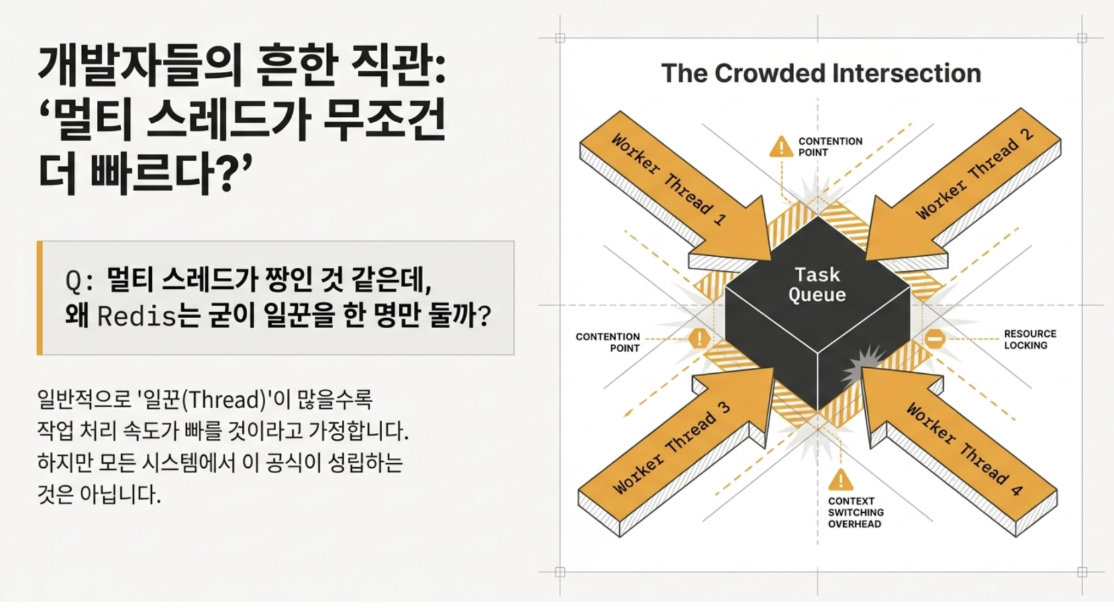
Q 멀티 스레드가 짱인 것 같은데, 왜 Redis는 굳이 일꾼을 한 명만 두는 방식을 택했을까
- 여러 스레드가 동시에 데이터에 접근하면 데이터가 꼬일 수 있어서 그걸 막으려고 그런 것
→ 멀티 스레드는 컨텍스트 스위칭(Context Swtiching) 오버헤드와, 여러 스레드가 락(Lock)을 차지하려고 싸우는 경합(Lock Contention) 문제가 발생함 ⇒ Redis는 메모리 연산 자체가 워낙 빠르기 때문에 락 걸고 기다릴 바엔 혼자서 미친 듯이 처리하는 게 더 낫다고 판단함
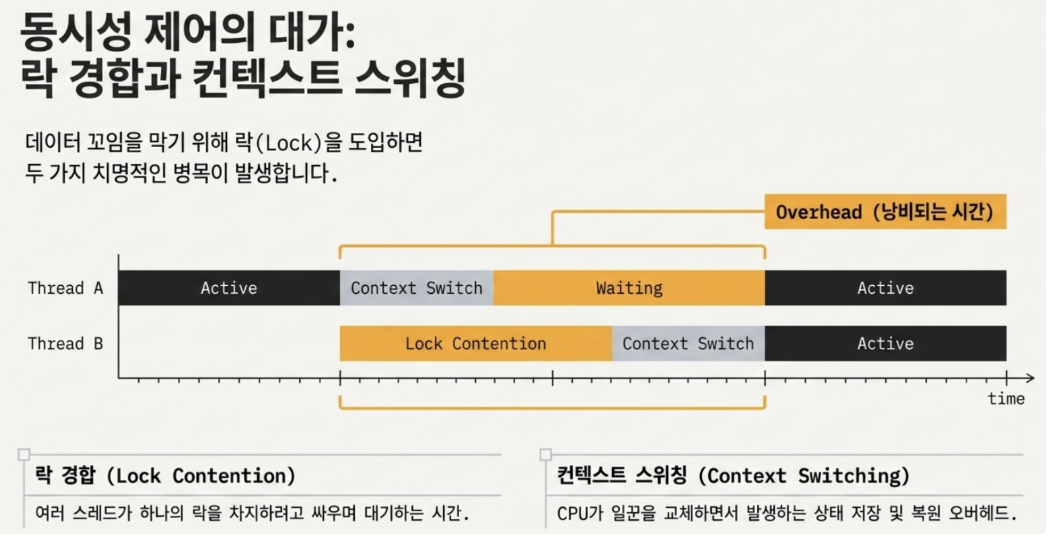
- 이벤트 루프 기반 다중화(Multiplexing)의 이해
- 식당의 웨이터로 비유하면
- 다중화를 장착한 Redis는 손님이 메뉴를 고를 떄까지 기다리지 않고, 이벤트가 발생할 때만 번개처럼 움직임
- 식당의 웨이터로 비유하면
- 트래픽 상황 시간 순서 처리 흐름 비교
동일한 시간에 3개의 쓰기 요청(A, B, C)이 들어왔다고 가정할 때,
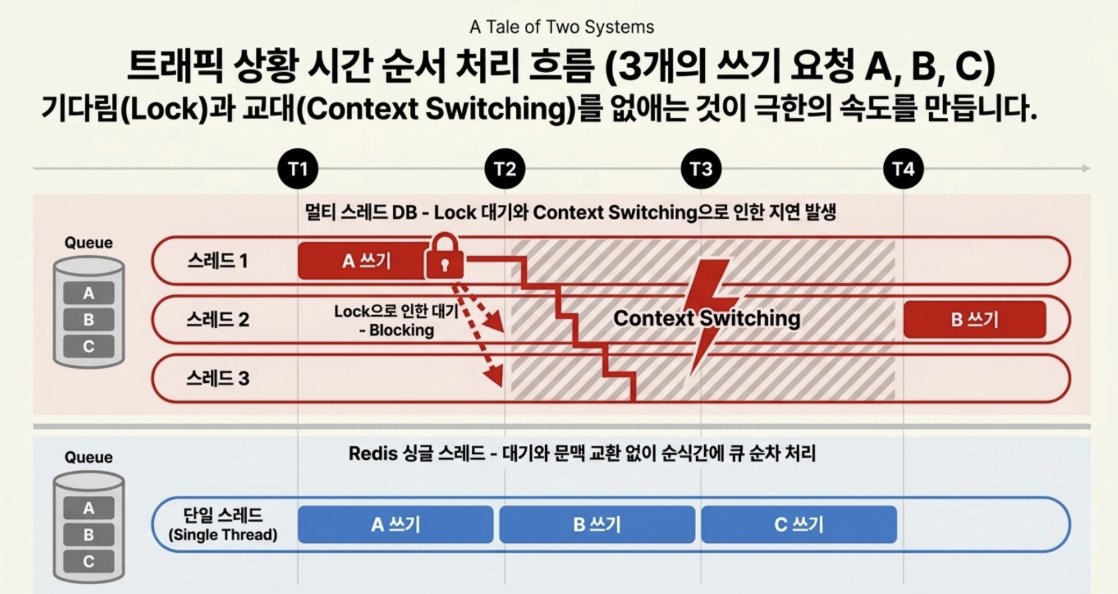
- Redis 싱글 스레드 → 락 대기나 문맥 교환 없이 순식간에 원자성(Atomicity)을 보장하며 처리 완료!
캐싱 전략 시나리오
파레토 법칙(Pareto Principle)에 따라 전체 요청의 80%는 20%의 데이터에서 발생함
 이 20% 를 캐싱하는 전략을 볼 것임
이 20% 를 캐싱하는 전략을 볼 것임
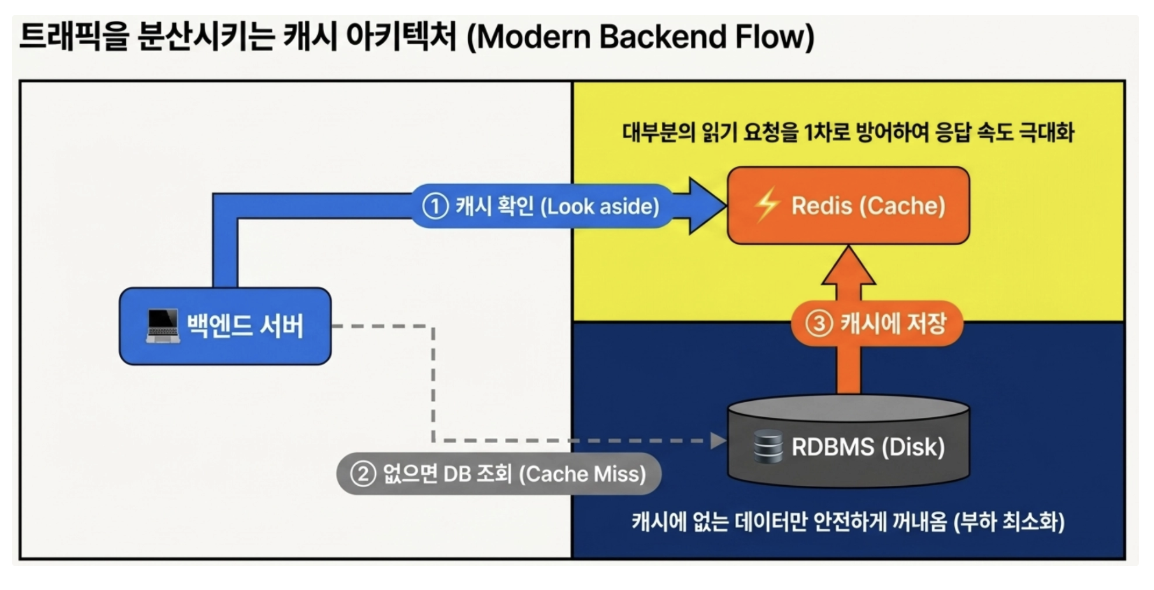
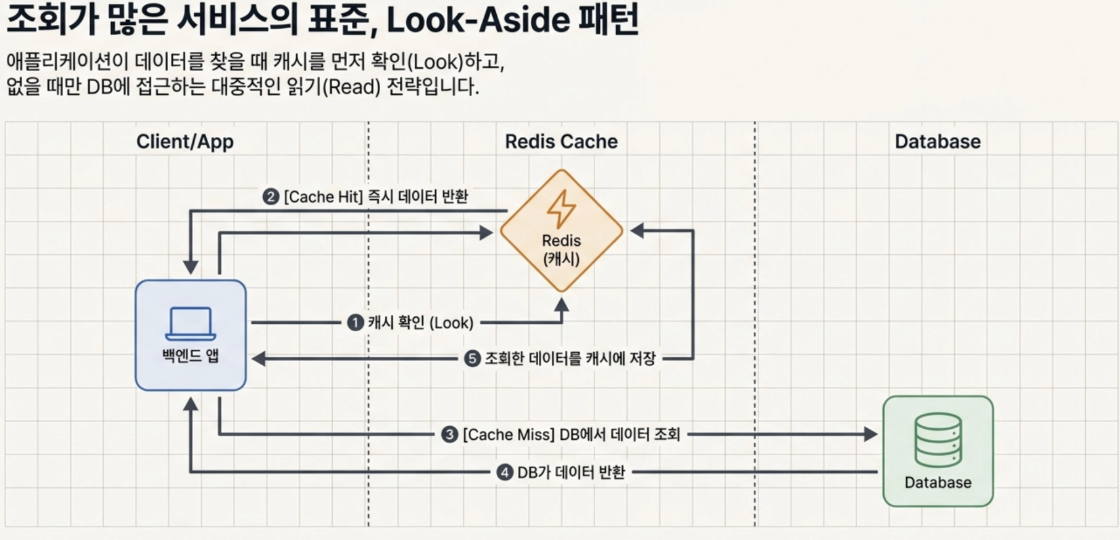
- Look-Aside (Cache-Aside) 패턴
애플리케이션이 데이터를 찾을 때 캐시를 먼저 확인(Look)하고, 없으면 DB에서 가져와 캐시에 밀어넣는 가장 대중적인 전략
조회(Read)가 많은 서비스에 적합
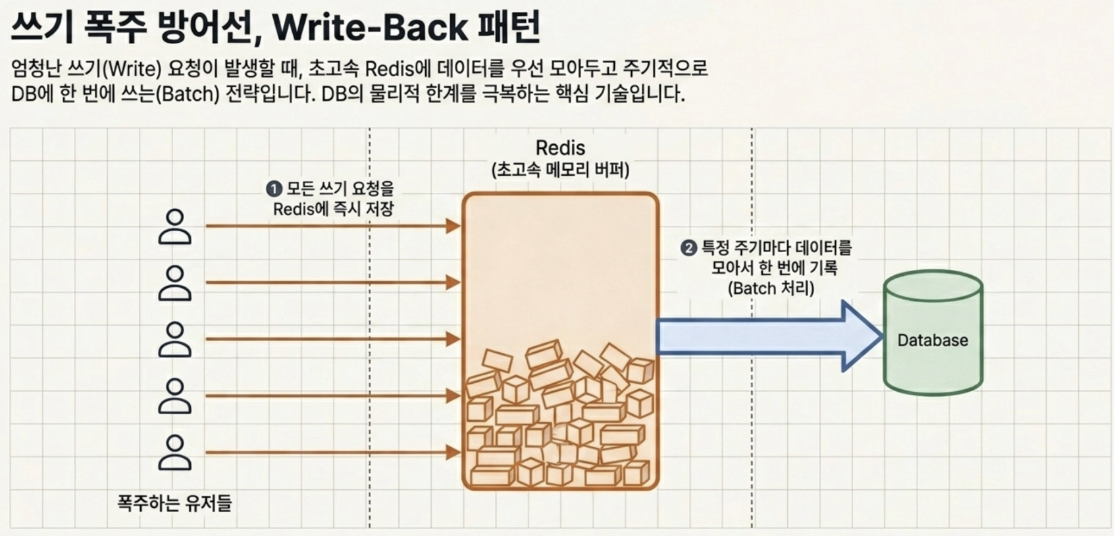
- Write-Back 패턴
모든 데이터를 우선 엄청나게 빠른 Redis에만 몰아넣고, 주기적으로 모아서 DB에 한 번에 쓰는(Batch) 전략
유튜브 라이브 방송의 ‘좋아요’ 폭주 같은 엄청난 쓰기(Write) 요청 시 DB가 터지는 걸 막아줌
캐시 무효화(Cache Invalidation)는 언제, 어떻게 하는가?
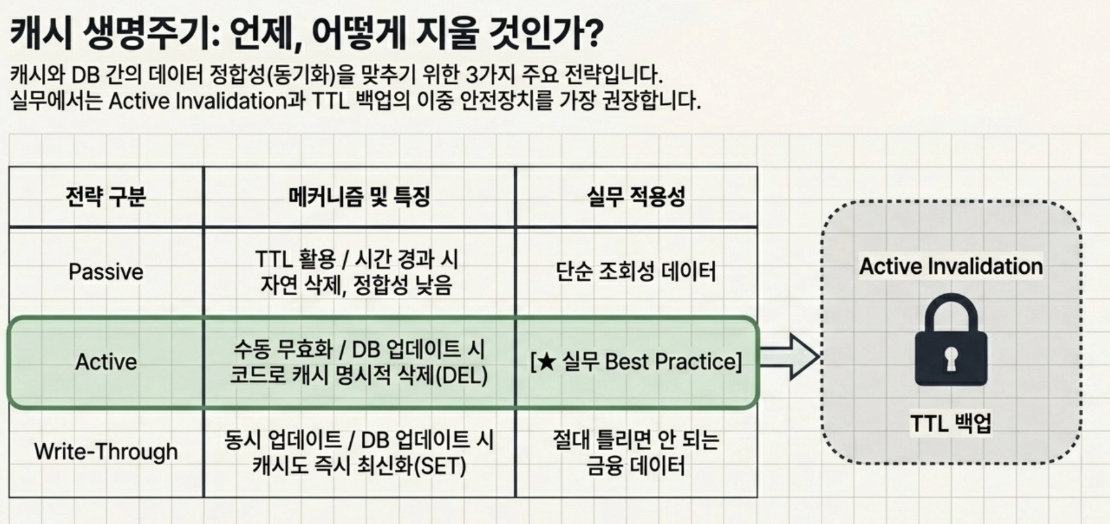
Passive Invalidation (TTL 활용): 가장 쉬운 방법은 TTL을 걸어두어 시간이 지나면 자엽스럽게 지워지도록 내버려두는 것
Active Invalidation (수동 무효화): DB에 UPDATE나 DELETE 쿼리가 발생할 때, 백엔드 애플리케이션 코드에서 명시적으로 Redis의
DEL명령어를 호출해 캐시를 날려버리는 방식Write-Through의 활용: DB를 업데이트 할 때 아예 Redis 캐시의 내용도 최신 값으로 같이
SET해버리는 방법도 있음
→ 실무에서는 주로 Active Invalidation을 기본으로 하되, 시스템 장애로 인해 삭제 로직이 실패할 경우를 대비하여 백업 차원에서 TTL을 함께 걸어두는 이중 안전장치를 가장 많이 사용함
- TTL(만료 시간)은 얼마로 설정해야 적절한가?
Q 만약 쇼핑몰의 ‘이용약관’ 페이지와 ‘비트코인 실시간 시세’ 페이지를 캐싱한다면, TTL을 각각 어떻게 주면 좋을까
- 이용약관은 잘 안 변하니까 길게 주고, 비트코인 시세는 계속 변하니까 아주 짧게 주어야할 것
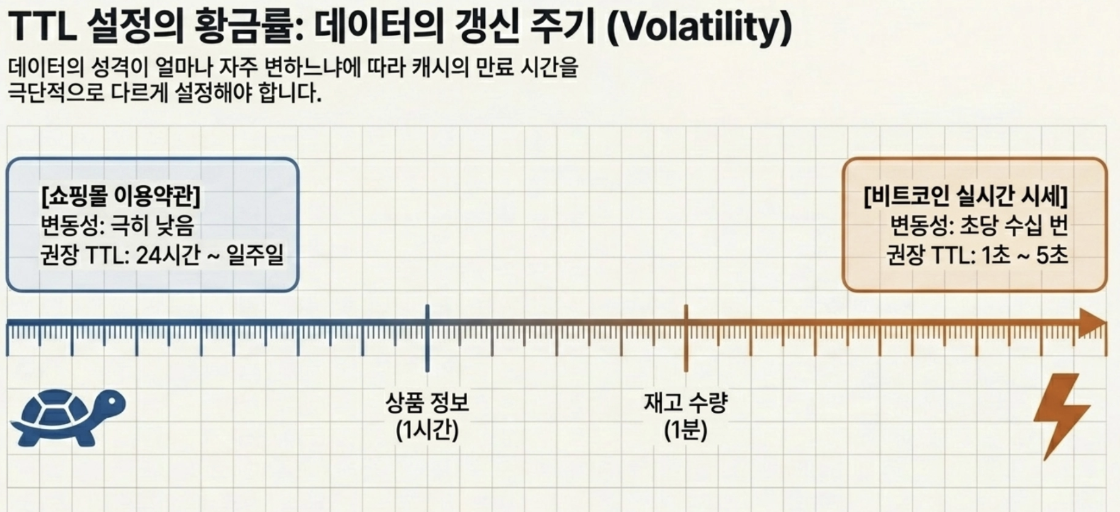
→ 데이터의 갱신 주기(Volatility)에 따라 TTL을 다르게 가져가야 함
캐시 스태피드(Cache Stampede) 현상 - 치명적 함정
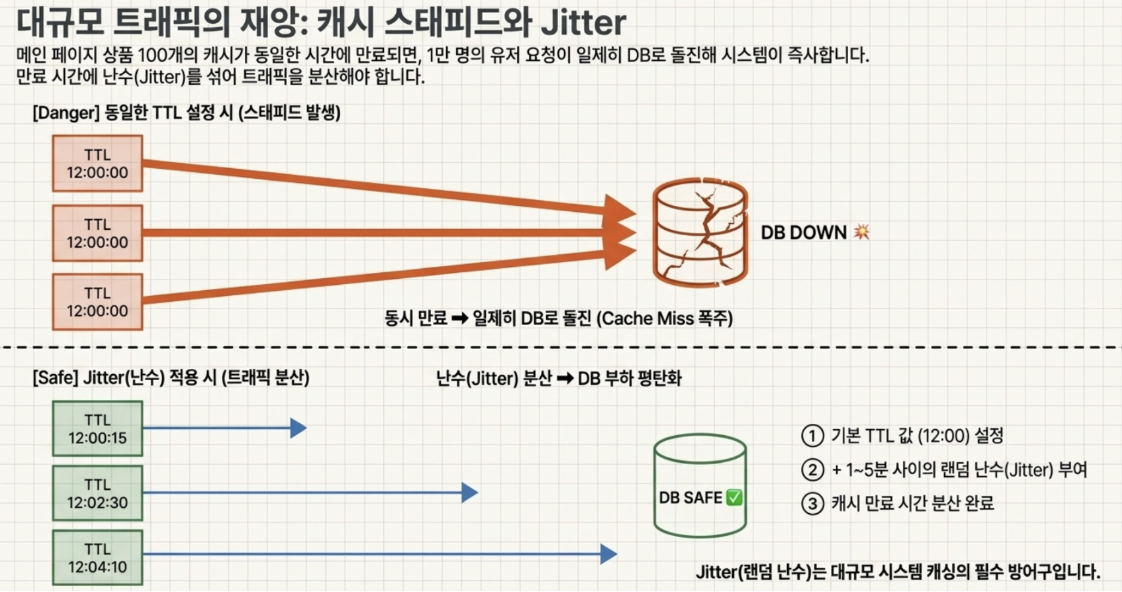
- 만약 메인 페이지에 노출되는 상품 100개의 캐시 TTL을 똑같이 오후 12시 정각으로 설정해두면 어떤 일이 벌어질까
12시가 되는 순간 캐시 100개가 동시에 날아감
이때 1초에 1만 명의 유저가 접속해있다면, 1만 명의 요청이 동시에 Cache Miss를 내며 DB로 돌진함 → DB는 그 순간 즉사(Down)하게 됨
→ 따라서 실무에서 대량의 데이터에 TTL을 설정할 때는 기본 TTL 값에 1~5분 사이의 랜덤한 난수(Jitter)를 더해서 설정해야함
- 이렇게 하면 캐시 만료 시간이 분산되어 DB에 부하가 한꺼번에 몰리는 것을 방지할 수 있음
- 만약 메인 페이지에 노출되는 상품 100개의 캐시 TTL을 똑같이 오후 12시 정각으로 설정해두면 어떤 일이 벌어질까
자료구조 5종 실전 예시
인기 많은 쇼핑몰을 가정하여 각 자료구조를 명령어와 함께 매핑해볼 예정
- String (문자열)
- 단순한 텍스트나 카운터를 저장할 때 씀
Q 쇼핑몰 메인 페이지에 ‘오늘의 총 방문자 수’를 보여줘야 한다면, 어떤 명령어로 구현할까 →
INCR이라는 원자적 명령어를 쓰면 동시성 문제 없이 완벽하게 카운팅이 가능함
List (리스트)
순서가 있는 데이터 큐
양 끝 삽입/삭제는 빠르지만 중간 삽입은 느림
예시: 최근 본 상품 → 유저가 페이지를 이동할 때마다 상품을 리스트 앞에 넣고, 오래된 것은 잘라냄
1 2 3 4 5 6 7
# 유저(999)가 상품(123)을 최근에 봤습니다. 리스트 맨 앞에 밀어 넣습니다. redis> LPUSH recent_views:user:999 item:123 (integer) 1 # 최근 본 상품은 딱 5개만 유지하도록 나머지는 잘라냅니다(Trim). redis> LTRIM recent_views:user:999 0 4 OK
Set (집합)
순서가 없고 중복을 허용하지 않음
예시: 선착순 이벤트 응모 → 1인당 1번만 참여 가능한 이벤트 응모자를 모을 때 중복을 원천 차단함
1 2 3 4 5 6 7
# 이벤트(event_x)에 유저(999)가 응모했습니다. redis> SADD event_x:participants user:999 (integer) 1 # 유저(999)가 또 응모 버튼을 연타했지만, 중복이므로 무시됩니다. redis> SADD event_x:participants user:999 (integer) 0
- 주의할 함정: 데이터가 수백만 개가 쌓였을 때 모든 아이템을 한 번에 가져오는
SMEMBERS를 날리면 전체 시스템이 멈춤 →SSCAN으로 나눠서 가져와야 함
- 주의할 함정: 데이터가 수백만 개가 쌓였을 때 모든 아이템을 한 번에 가져오는
Sorted Set (ZSET, 정렬된 집합)
Set에 ‘점수(Score)’라는 개념을 추가해서, 점수 순서대로 자동 정렬해주는 핵심 자료구조
예시: 실시간 구매왕 랭킹 → 유저의 누적 구매액을 Score로 삼아 실시간 랭킹을 만듦
1 2 3
# 유저(999)가 50,000원어치 물건을 사서 랭킹 보드에 점수를 누적합니다. redis> ZINCRBY daily_ranking 50000 user:999 "50000"
주의할 함정: 점수(Score)는 실수(Double) 타입으로 저장됨 → 자바의 Long 최댓값 같은 거대한 정수를 넣으면 정밀도 오류가 발생해 숫자가 바뀔 수 있으니 매우 주의해야함
Hash (해시)
하나의 key 안에 여러 개의 필드(Field)와 값(Value)을 넣을 수 있는 구조
예시: 장바구니 → 특정 유저의 장바구니에 담긴 상품 ID를 필드로, 수량을 값으로 저장함
1 2 3 4
# 유저(999)의 장바구니에 상품(123) 2개, 상품(456) 1개를 담습니다. # (Redis 4.0 이상에서는 HMSET 대신 HSET을 권장) redis> HSET cart:user:999 item:123 2 item:456 1 OK
실무 사례: 배달의 민족 B마트 분산 락
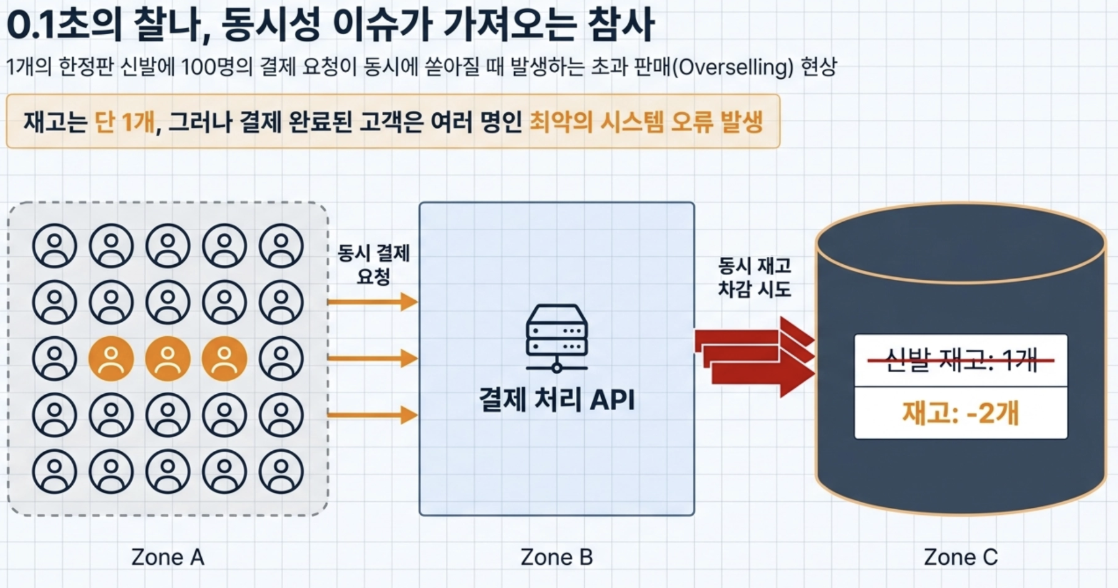
Q 만약 쇼핑몰에 딱 1개 남은 한정판 신발이 있는데, 100명이 0.1초의 오차도 없이 동시에 결제 버튼을 누르면 어떻게 될까
- 재고는 1개인데, 결제 처리가 동시에 돼서 여러 명한테 팔려버림 (초과 판매 현상)
→ 분산 락(Distributed Lock)이라는 기술을 사용해 위 같은 현상을 막아야함
- 국내 대형 서비스 배달의 민족 ‘B마트’의 WMS(창고 관리 시스템) 사례
B마트는 중앙 물류센터(DC)에서 지역 거점 센터(PPC)로 상품 재고를 끝없이 이관함
이때 관리자 A는 재고를 거점 센터로 할당하려고 하고, 관리자 B는 창고 사정상 이를 ‘취소’하려는 요청을 동시에 낼 수 있음
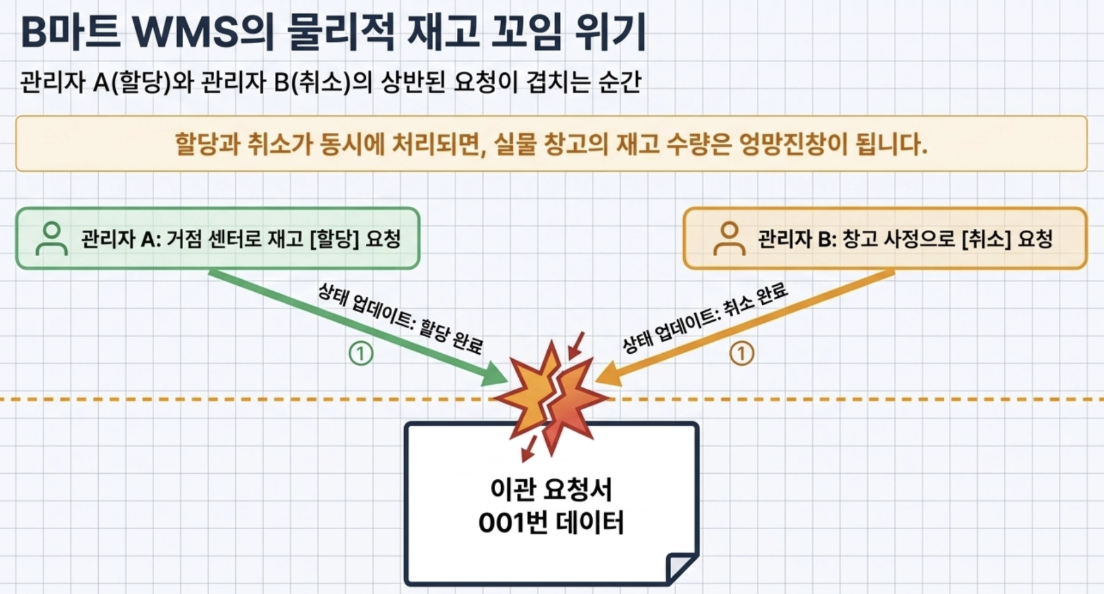
- 이때 시스템이 꼬여서 할당도 되고 취소도 돼버리면 물리적인 재고 수량이 엉망진창이 됨
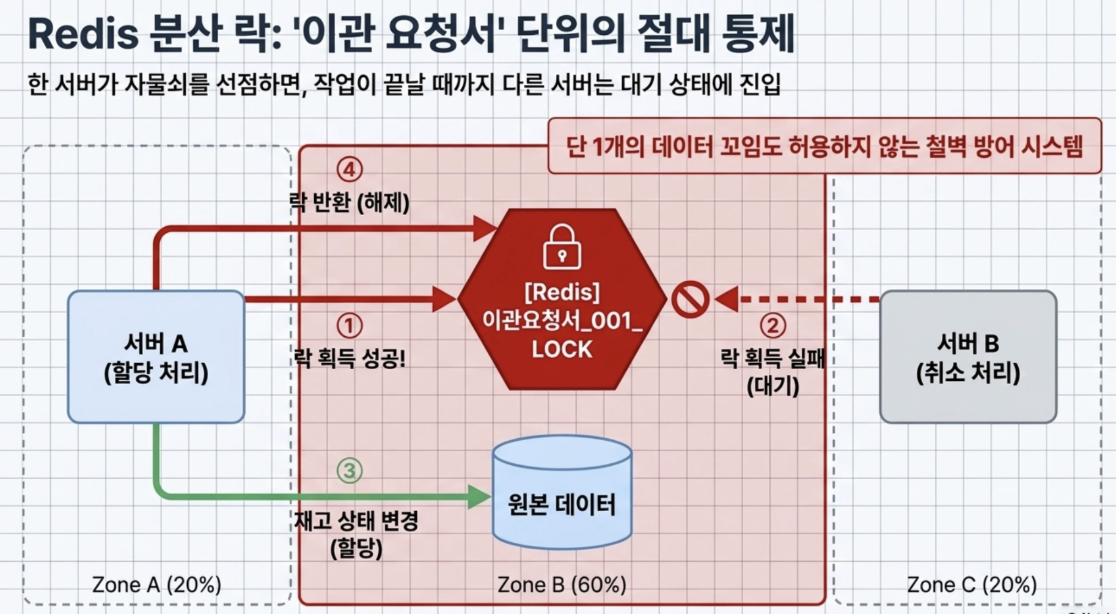
- Redis 분산 락을 통한 해결
배달의 민족은 이 문제를 막기 위해 ‘이관 요청서’ 단위로 Redis 분산 락을 걸었음
- 어느 한쪽 서버가 먼저 이관 요청서 001번에 대해 Redis로부터 락을 획득하면, 다른 서버는 그 자물쇠가 풀릴 때까지 결코 해당 재고의 상태를 변경할 수 없게 막아둔 것
이를 통해 단 1개의 데이터도 꼬임없이 동시성 이슈를 완벽히 통제함
Redis가 없었다면?
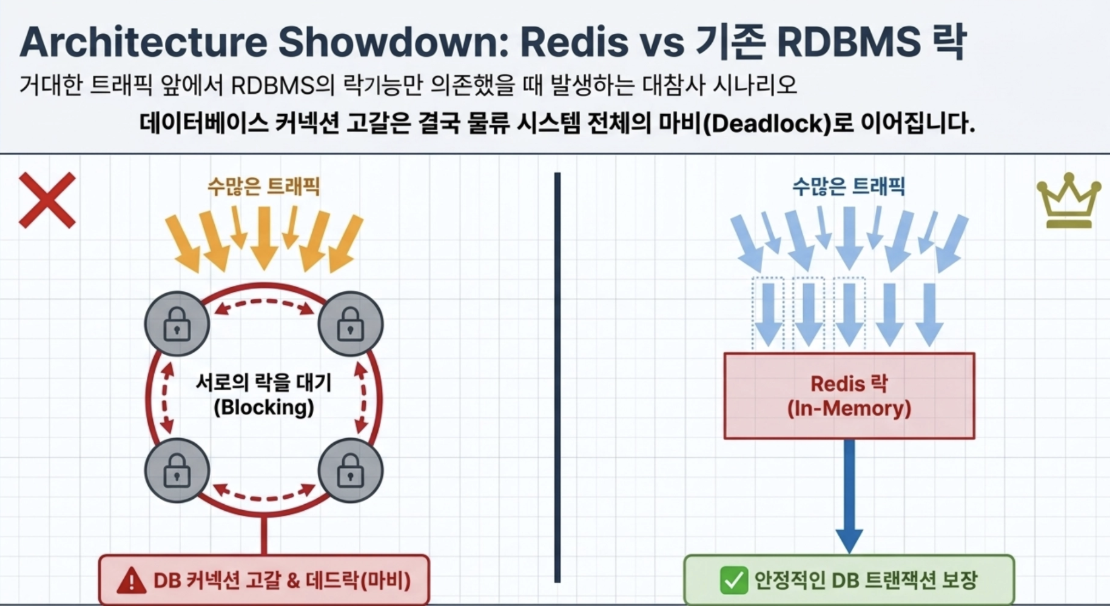
- Redis의 분산 락 없이 기존의 MySQL(RDBMS)의 락 기능만으로 이 거대한 트래픽의 재고 처리를 감당하려 했다면
수많은 재고 할당/취소 요청이 DB에 몰리면서 서로 행(Row)에 락을 걸려고 아우성을 쳤을 것임
결국 수많은 쿼리들이 대기(Blocking) 상태에 빠지며 DB 커넥션 풀이 고갈되고, 최악의 경우 서로가 서로의 락을 물고 늘어지는 데드락(Deadlock)에 빠져 B마트 물류 시스템 전체가 마비되는 대참사가 일어났을 것
- Redis의 분산 락 없이 기존의 MySQL(RDBMS)의 락 기능만으로 이 거대한 트래픽의 재고 처리를 감당하려 했다면
Redis 코어 아키텍처와 기초 마무리
Redis는 메모리를 사용하여 디스크 연산을 없애고, 이벤트 루프 기반 싱글 스레드를 통해 컨텍스트 스위칭 지연 없이 원자성(Atomicity)을 완벽히 보장한다.
트래픽과 요구사항에 맞게 캐시 무효화 전략과 Jitter를 더한 TTL을 설정하여 캐시 스태피드(Cache Stampede)에 의한 DB 다운을 막아야 한다.
단순한 데이터 저장소를 넘어 분산 시스템의 동시성 문제를 해결하는 분산 락(Distributed Lock) 등 MSA 아키텍처의 필수 미들웨어로 활약한다.
질문 & 오류
Q 기존 디스크 기반 DB는 멀티스레드라서 락이 필요하고 느리다고 들었는데, Redis는 싱글 스레드라면서 왜 분산 락을 또 사용하나요?
- Redis의 싱글 스레드는 Redis 내부에서 명령(Command)을 처리하는 방식을 의미함
즉, Redis는 한 번에 하나의 명령만 순서대로 처리하기 때문에 여러 스레드가 동시에 같은 메모리 데이터를 수정하면서 발생하는 충돌이 적음
Redis 명령 자체는 원자적(Atomic)으로 실행됨
- 하지만 실제 서비스 로직은 보통 여러 단계로 이루어짐
재고 조회
재고가 있는지 확인
주문 생성
재고 감소
→ 결과적으로 재고보다 많은 주문이 발생할 수 있음
이 문제를 막기 위해 사용하는 것이 분산 락(Distributed Lock)
분산 락은 “지금 이 작업은 한 서버만 수행 가능”하도록 제한하는 역할을 함
1 2 3 4 5 6 7
서버 A: 락 획득 성공 서버 B: 락 획득 실패 → 대기 서버 A: - 재고 확인 - 주문 생성 - 재고 감소 작업 완료 후 락 반납
핵심 차이
개념 의미 Redis 싱글 스레드 Redis 내부 명령 처리 방식 DB 락 DB 내부 트랜잭션 충돌 방지 Redis 분산 락 여러 서버/요청 간 동시 작업 제어
댓글
궁금한 점, 피드백, 오류 제보를 남겨 주세요.