[TIL] Spring Boot 모니터링 환경 구축하기
For the English version of this post, see here.
학습 배경
애플리케이션을 개발하는 것만큼 중요한 것은 배포 이후 안정적으로 운영하는 것이다.
서비스가 정상적으로 동작하는지, 메모리나 CPU 사용량이 과도하지 않은지, 장애가 발생했을 때 빠르게 알아차릴 수 있는지 확인하려면 모니터링 환경이 필요하다.
이번 학습에서는 Spring Boot 애플리케이션의 상태를 확인하기 위해 Actuator를 사용하고, Prometheus로 메트릭을 수집한 뒤 Grafana로 시각화하는 과정을 실습했다.
추가로 애플리케이션 장애 상황을 Slack 알림으로 받아보고, Loki를 이용해 애플리케이션 로그까지 Grafana에서 확인하는 흐름을 학습했다.
모니터링이란?
모니터링은 시스템의 성능, 안정성, 가용성을 지속적으로 관찰하고 측정하는 과정이다.
단순히 서버가 켜져 있는지만 확인하는 것이 아니라, 애플리케이션 상태, 메모리 사용량, 요청 수, 에러 로그, 네트워크 상태 등을 함께 확인한다.
모니터링이 필요한 이유
모니터링이 필요한 가장 큰 이유는 장애를 빠르게 발견하고 대응하기 위해서이다.
예를 들어 사용자가 서비스를 이용하는 중에 서버가 내려갔는데 개발자가 이를 늦게 알게 되면, 그 시간 동안 서비스는 계속 장애 상태로 남아있게 된다.
하지만 모니터링과 알림이 설정되어 있다면, 서버 상태가 비정상으로 바뀌는 순간 Slack 같은 채널로 알림을 받아 빠르게 대응할 수 있다.
또한 모니터링은 성능 병목을 찾는 데도 도움이 된다.
CPU 사용량이 높은지, 메모리가 계속 증가하는지, 요청 처리 시간이 느려지는지 확인하면서 애플리케이션의 문제 원인을 더 빠르게 파악할 수 있다.
Spring Boot Actuator
Actuator란?
Spring Boot Actuator는 Spring Boot 애플리케이션의 상태와 성능 정보를 확인할 수 있도록 여러 엔드포인트를 제공하는 기능이다.
대표적으로 다음과 같은 정보를 확인할 수 있다.
/actuator/health: 애플리케이션 상태 확인/actuator/metrics: 메트릭 정보 확인/actuator/env: 환경 변수 및 설정 정보 확인/actuator/loggers: 로깅 설정 확인/actuator/prometheus: Prometheus가 수집할 수 있는 형식의 메트릭 제공
즉, Actuator는 애플리케이션 내부 상태를 외부에서 확인할 수 있도록 열어주는 역할을 한다.
Actuator가 필요한 이유
일반적인 Spring Boot 애플리케이션은 실행 중인지 아닌지만으로 상태를 판단하기 어렵다.
서버는 켜져 있어도 DB 연결이 끊겼거나, 메모리 사용량이 비정상적으로 높거나, 특정 요청에서 에러가 계속 발생할 수 있다.
Actuator를 사용하면 애플리케이션의 상태 정보를 엔드포인트로 확인할 수 있기 때문에 운영 환경에서 상태 점검을 자동화할 수 있다.
사용 방법
build.gradle에 Actuator 의존성을 추가한다.
1
2
3
4
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'org.springframework.boot:spring-boot-starter-web'
}
application.properties 또는 application.yml에 Actuator 엔드포인트 노출 설정을 추가한다.
1
2
3
4
5
spring.application.name=sample
server.port=8080
management.endpoints.web.exposure.include=*
management.endpoint.health.show-details=always
브라우저에서 다음 주소로 접속하여 Actuator 엔드포인트 목록을 확인할 수 있다.
1
http://localhost:8080/actuator
헬스 체크는 다음 주소에서 확인할 수 있다.
1
http://localhost:8080/actuator/health
/actuator접속 결과 화면
/actuator/health접속 결과 화면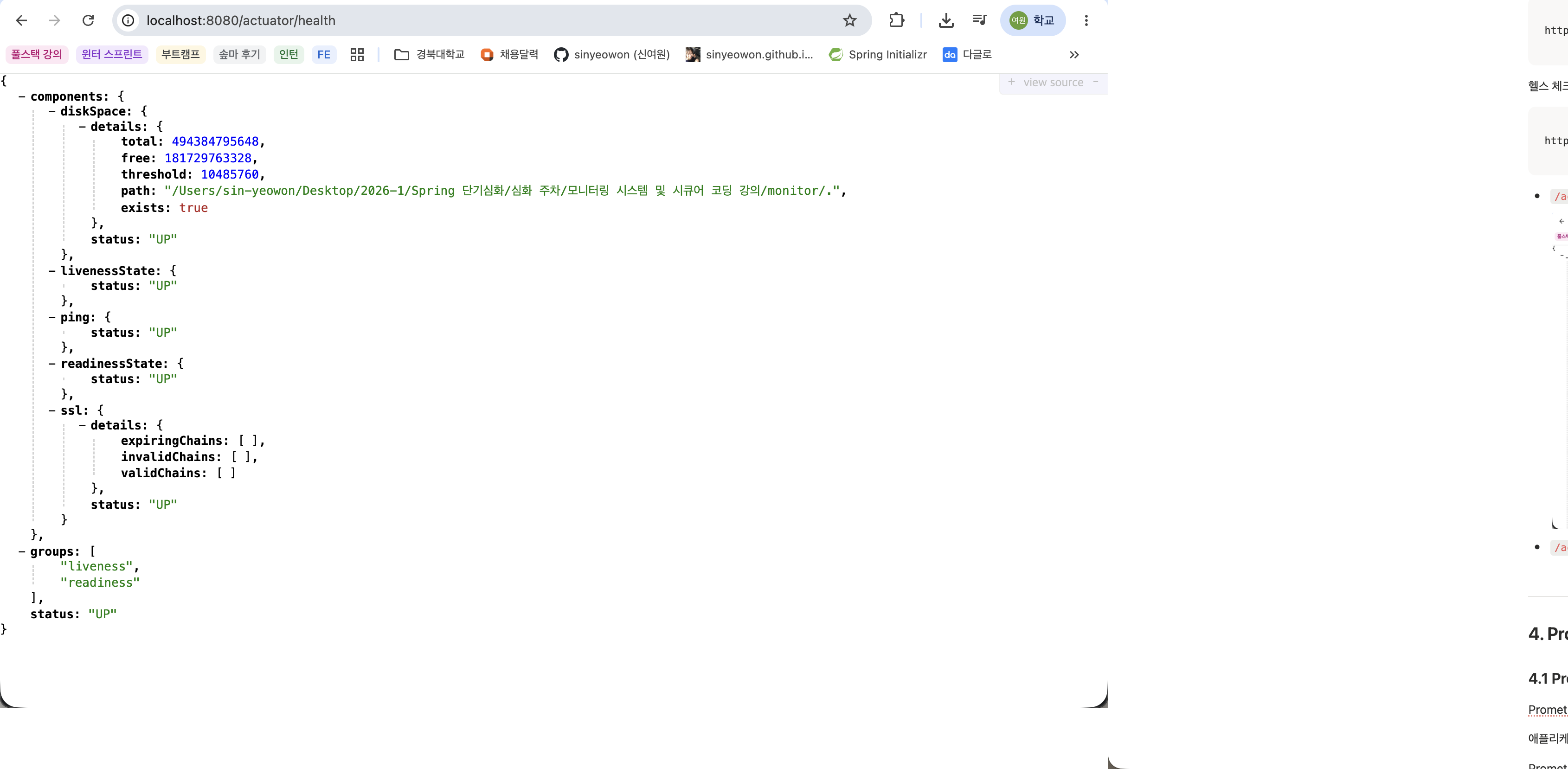
Prometheus
Prometheus란?
Prometheus는 시스템 모니터링과 경고를 위한 오픈소스 도구이다.
애플리케이션이나 서버에서 제공하는 메트릭 데이터를 주기적으로 수집하고 저장한다.
- 메트릭 데이터
- 시스템 상태를 숫자로 기록한 데이터
ex)
메트릭 의미 jvm_memory_used_bytesJVM이 사용 중인 메모리 http_server_requests_seconds_countHTTP 요청이 몇 번 들어왔는지 process_cpu_usage애플리케이션 CPU 사용률 upPrometheus가 앱을 정상 수집 중인지
Prometheus는 데이터를 직접 가져가는 pull 방식으로 동작한다.
즉, Spring Boot 애플리케이션이 메트릭을 제공하면 Prometheus가 일정 주기마다 해당 주소로 접근해서 데이터를 수집한다.
Prometheus가 필요한 이유
Actuator만 사용하면 애플리케이션의 현재 상태를 확인할 수는 있지만, 시간에 따라 값이 어떻게 변했는지 저장하고 분석하기는 어렵다.
Prometheus는 메트릭을 주기적으로 수집하고 저장하기 때문에 다음과 같은 분석이 가능하다.
애플리케이션이 언제부터 느려졌는지 확인
CPU, 메모리 사용량 변화 추적
요청 수와 에러 수 변화 확인
특정 조건에서 Alert 발생
즉, Actuator가 “상태를 보여주는 역할”이라면 Prometheus는 “그 상태를 계속 수집하고 저장하는 역할”을 한다.
Spring Boot에서 Prometheus 메트릭 노출하기
Prometheus가 Spring Boot 메트릭을 수집할 수 있도록 micrometer-registry-prometheus 의존성을 추가한다.
1
2
3
4
5
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'org.springframework.boot:spring-boot-starter-web'
runtimeOnly 'io.micrometer:micrometer-registry-prometheus'
}
설정 파일에 Prometheus 엔드포인트를 활성화한다.
1
2
3
4
5
6
spring.application.name=sample
server.port=8080
management.endpoints.web.exposure.include=*
management.endpoint.health.show-details=always
management.endpoint.prometheus.enabled=true
이후 다음 주소에서 Prometheus 형식의 메트릭을 확인할 수 있다.
1
http://localhost:8080/actuator/prometheus
/actuator/prometheus접속 결과 화면
Prometheus 설정 파일
Prometheus가 어떤 애플리케이션을 모니터링할지 설정하기 위해 prometheus.yml 파일을 생성한다.
1
2
3
4
5
6
7
8
9
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'spring-boot'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['host.docker.internal:8080']
여기서 job_name은 Prometheus에서 해당 수집 대상을 구분하는 이름이다.
metrics_path는 Spring Boot 애플리케이션에서 Prometheus 메트릭을 제공하는 경로이다.
targets에는 수집할 애플리케이션 주소를 적는다.
Docker 컨테이너에서 호스트 PC의 Spring Boot 애플리케이션에 접근해야 하기 때문에 host.docker.internal:8080을 사용했다.
Prometheus 실행
Docker를 사용하여 Prometheus를 실행한다.
1
2
3
4
5
docker run -d \
--name=prometheus \
- p 9090:9090 \
- v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
실행 후 다음 주소로 접속한다.
1
http://localhost:9090
Prometheus 메뉴에서 Status > Targets로 이동하면 Spring Boot 애플리케이션이 정상적으로 수집되고 있는지 확인할 수 있다.
Prometheus 메인 화면
Status > Targets에서 spring-boot 상태가 UP으로 표시된 화면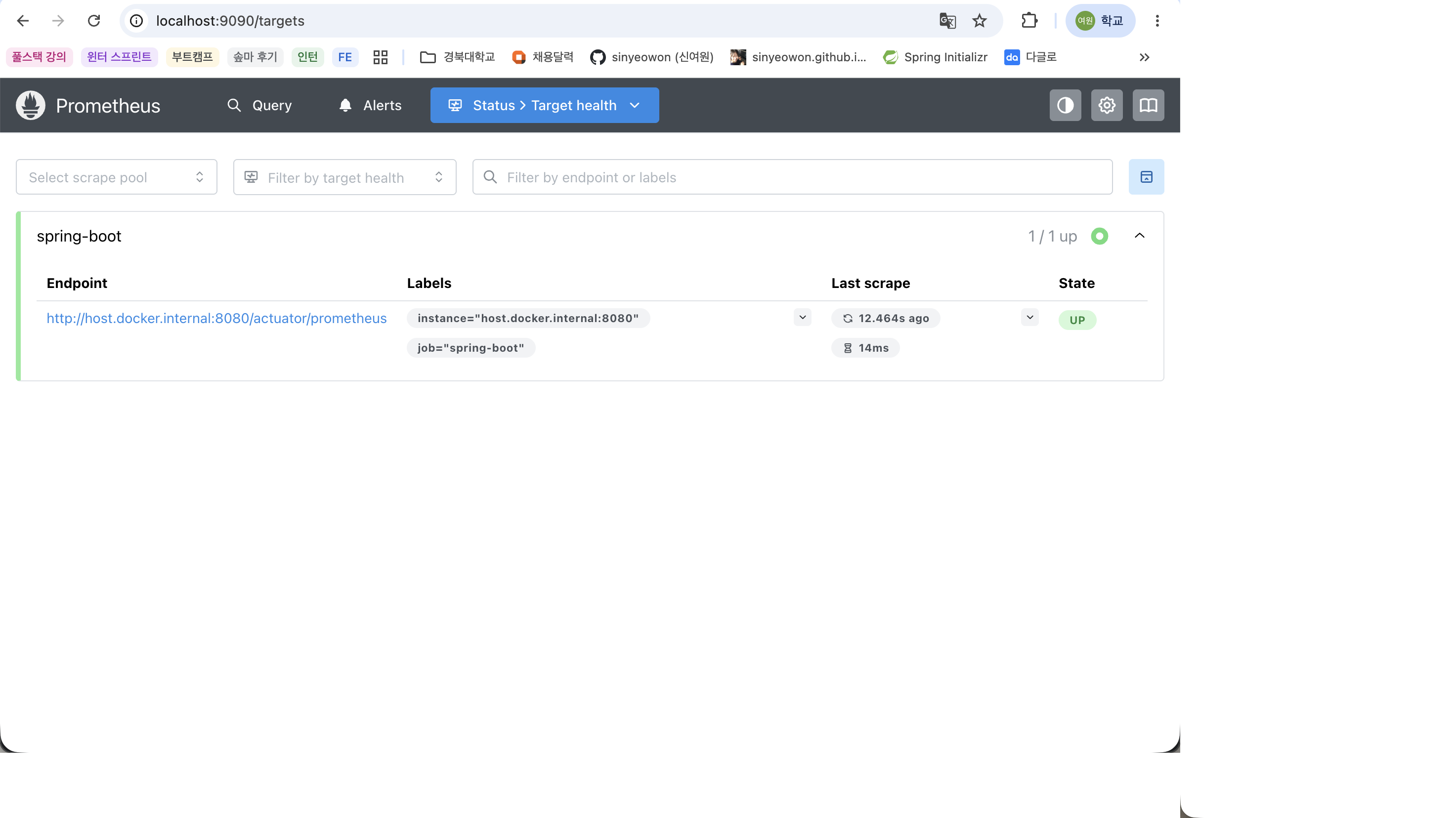
Grafana
Grafana란?
Grafana는 데이터를 시각화하고 모니터링할 수 있는 오픈소스 대시보드 도구이다.
Prometheus, Loki, MySQL, PostgreSQL 등 다양한 데이터 소스를 연결할 수 있다.
Prometheus가 메트릭 데이터를 수집하고 저장한다면, Grafana는 그 데이터를 사람이 보기 좋은 그래프와 대시보드로 보여주는 역할을 한다.
Grafana가 필요한 이유
Prometheus에서도 쿼리를 실행해 메트릭을 볼 수 있지만, 운영 중인 시스템을 계속 관찰하기에는 대시보드 형태가 훨씬 편하다.
Grafana를 사용하면 CPU 사용량, 메모리 사용량, 요청 수, 에러 수 등을 그래프와 차트로 확인할 수 있고, 특정 조건이 발생했을 때 알림을 보낼 수도 있다.
즉, Grafana는 모니터링 데이터를 “보기 쉽게 만드는 역할”을 한다.
Grafana 실행
Docker로 Grafana 컨테이너를 실행한다.
1
2
3
4
docker run -d \
--name=grafana \
- p 3000:3000 \
grafana/grafana
브라우저에서 다음 주소로 접속한다.
1
http://localhost:3000
기본 계정은 다음과 같다.
1
2
ID: admin
Password: admin
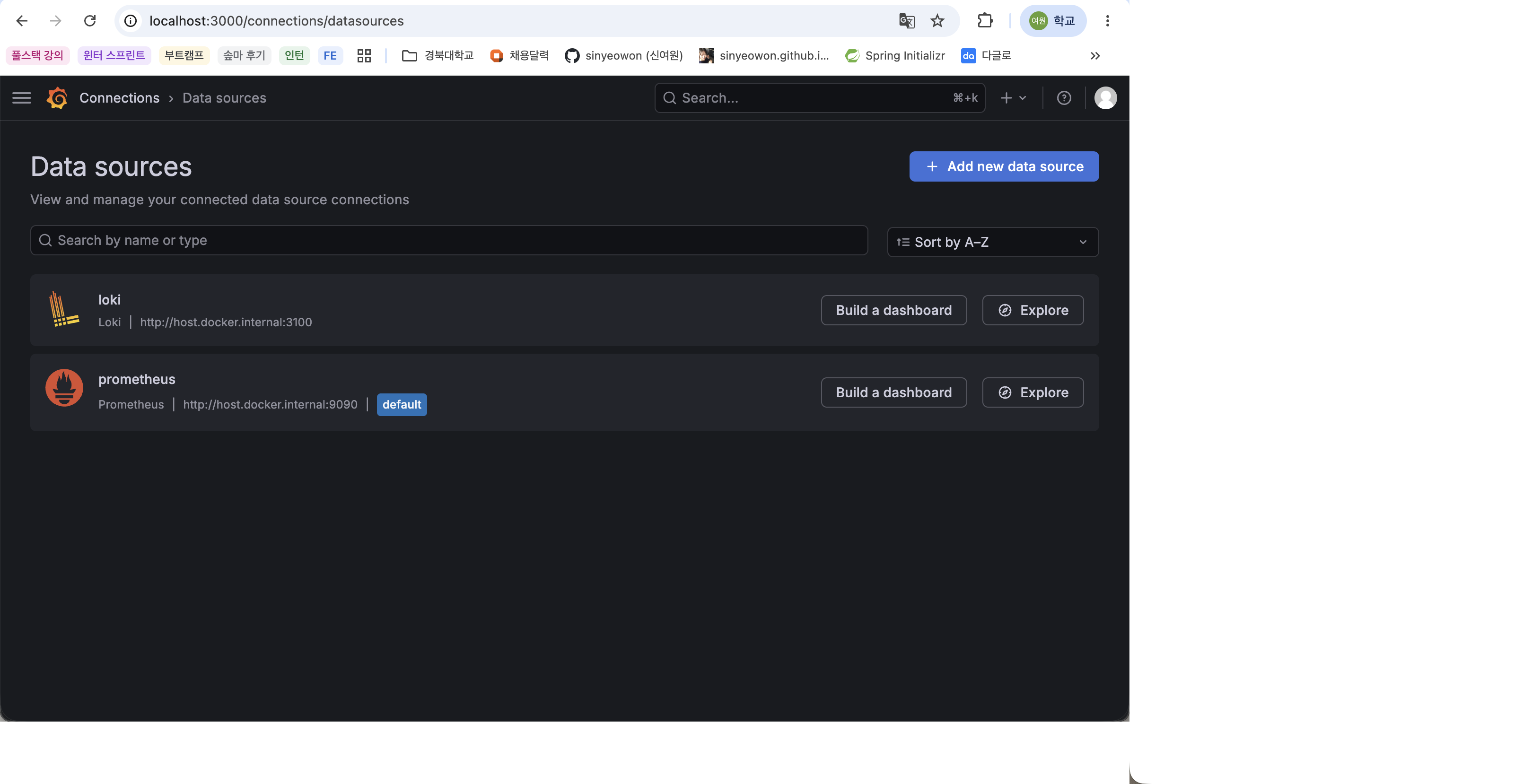
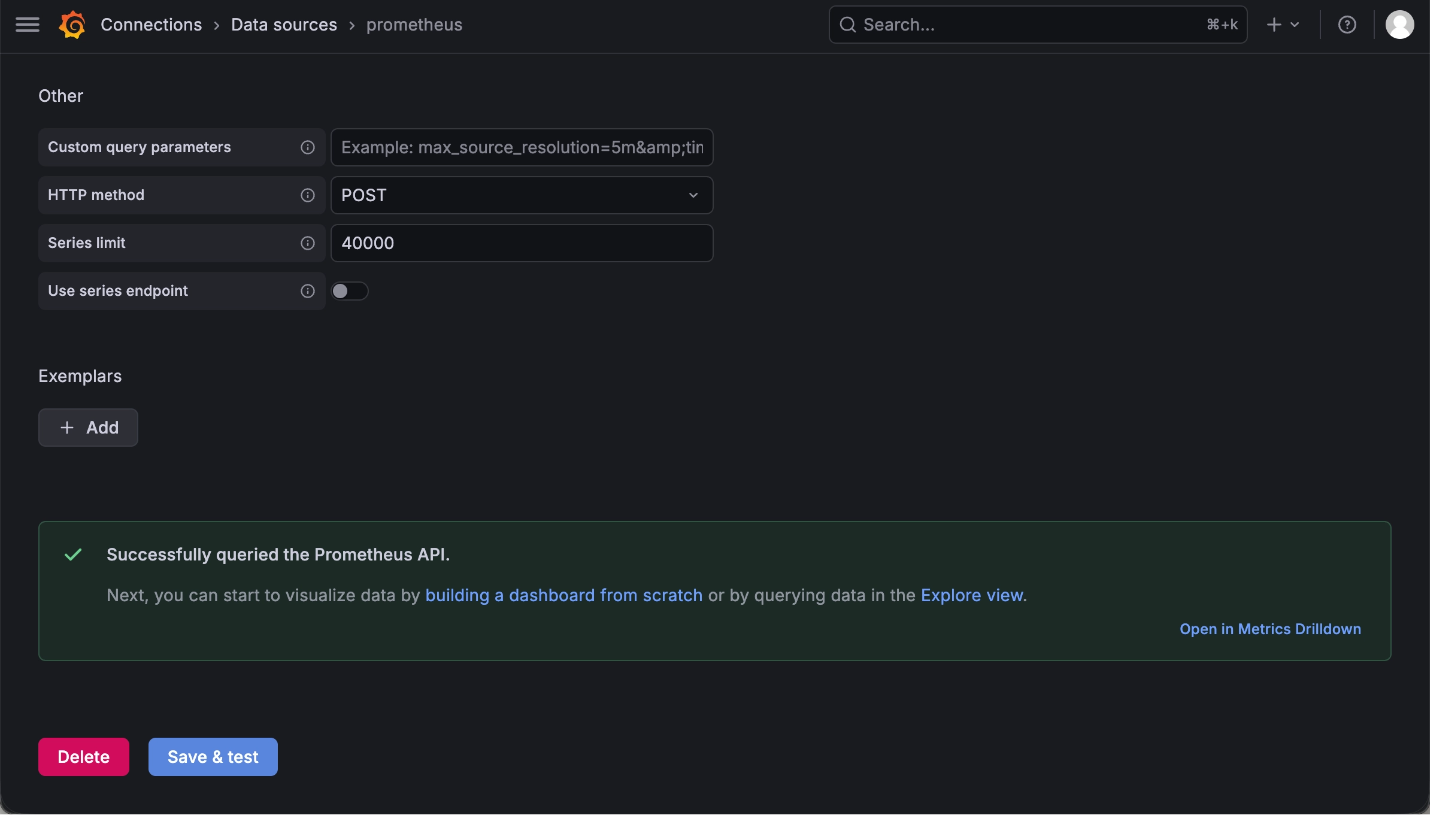
Prometheus 데이터 소스 연결
Grafana에서 Prometheus 데이터를 사용하려면 Data source를 추가해야 한다.
설정 순서는 다음과 같다.
Grafana 접속
Data sources 메뉴 이동
Prometheus 선택
Prometheus server URL 입력
Save & test 클릭
Prometheus가 Docker로 실행 중이므로 URL은 다음과 같이 입력할 수 있다.
1
http://host.docker.internal:9090
연결이 성공하면 Grafana에서 Prometheus 데이터를 조회할 수 있다.
Grafana 로그인 화면
Prometheus Data source 설정 화면
Save & test 성공 화면
Dashboard Import
Grafana에서는 이미 만들어진 대시보드를 가져와 사용할 수 있다.
Spring Boot 3용 대시보드로 19004를 입력하여 Import했다.
대시보드 Import 흐름은 다음과 같다.
Dashboards 메뉴 이동
New 또는 Import dashboard 선택
Dashboard ID
19004입력Load 클릭
Prometheus 데이터 소스 선택
Import 클릭
- Spring Boot 대시보드 생성 결과 화면
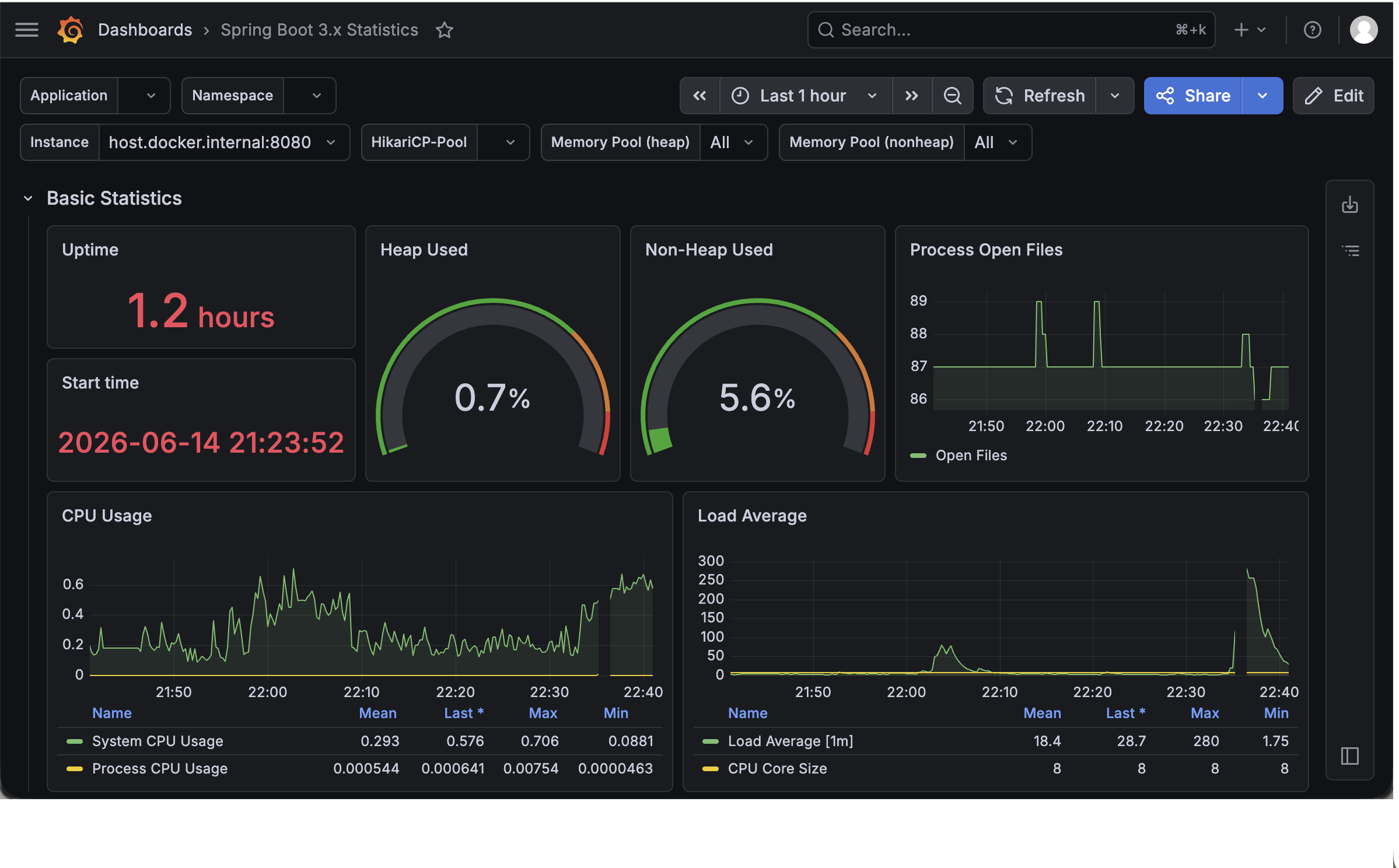
Grafana에서 Slack으로 Alert 보내기
Alert란?
Alert는 특정 조건이 만족되었을 때 알림을 보내는 기능이다.
예를 들어 Spring Boot 애플리케이션이 중지되면 Prometheus의 up 메트릭 값이 0이 되고, Grafana는 이 값을 기준으로 장애 상태를 판단할 수 있다.
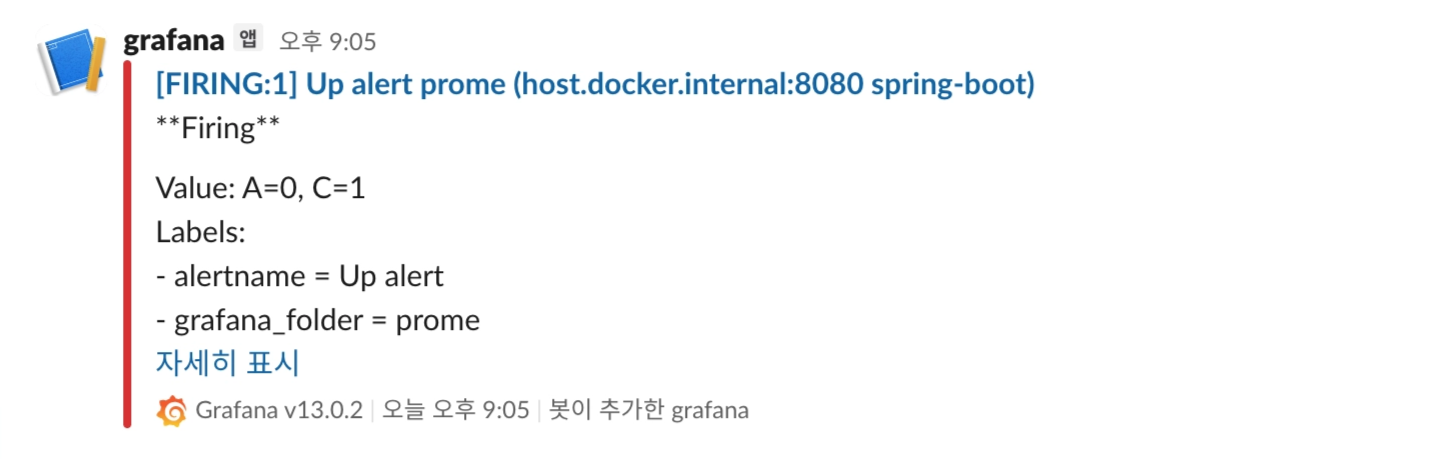
이번 실습에서는 Spring Boot 애플리케이션이 정지되었을 때 Slack으로 알림을 보내도록 설정했다.
Slack Alert가 필요한 이유
개발자가 계속 Grafana 대시보드를 보고 있을 수는 없다.
장애는 언제든 발생할 수 있기 때문에, 문제가 발생했을 때 Slack 같은 협업 도구로 즉시 알림을 받는 것이 중요하다.
Slack Alert를 설정하면 애플리케이션이 내려갔을 때 팀원들이 빠르게 상황을 인지하고 대응할 수 있다.
Slack App 및 Webhook 설정
Slack API에서 앱을 생성한 뒤 Incoming Webhooks를 활성화한다.
이후 알림을 받을 Slack 채널을 선택하고 Webhook URL을 생성한다.
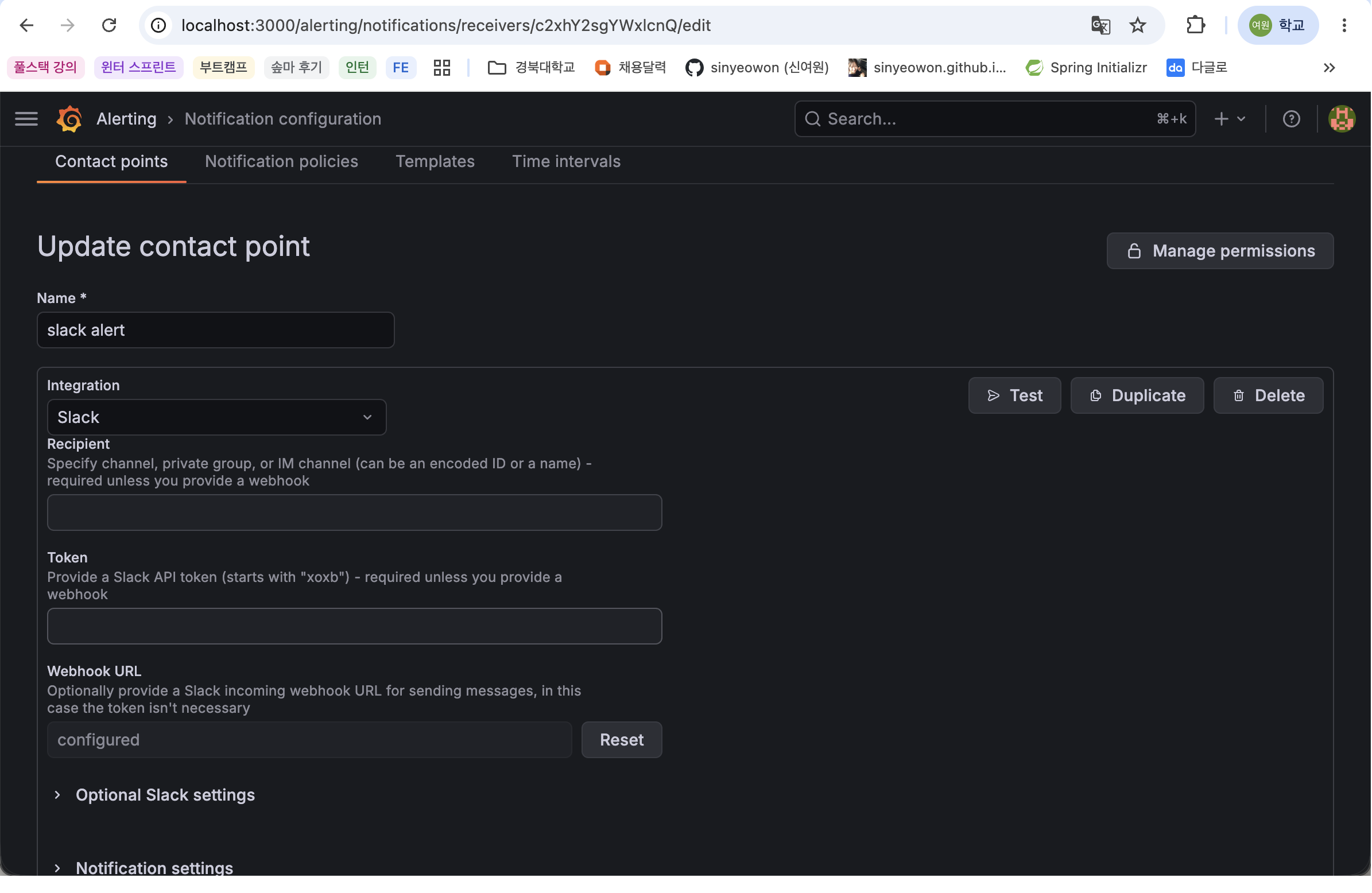
Grafana에서는 이 Webhook URL을 Contact point에 등록한다.
Grafana Contact point 설정
Grafana에서 다음 순서로 설정한다.
Alerting 메뉴 이동
Contact points 선택
Add contact point 클릭
Integration을 Slack으로 선택
Webhook URL 입력
Test 버튼으로 Slack 메시지 전송 확인
Save contact point 클릭
Slack App 생성 화면
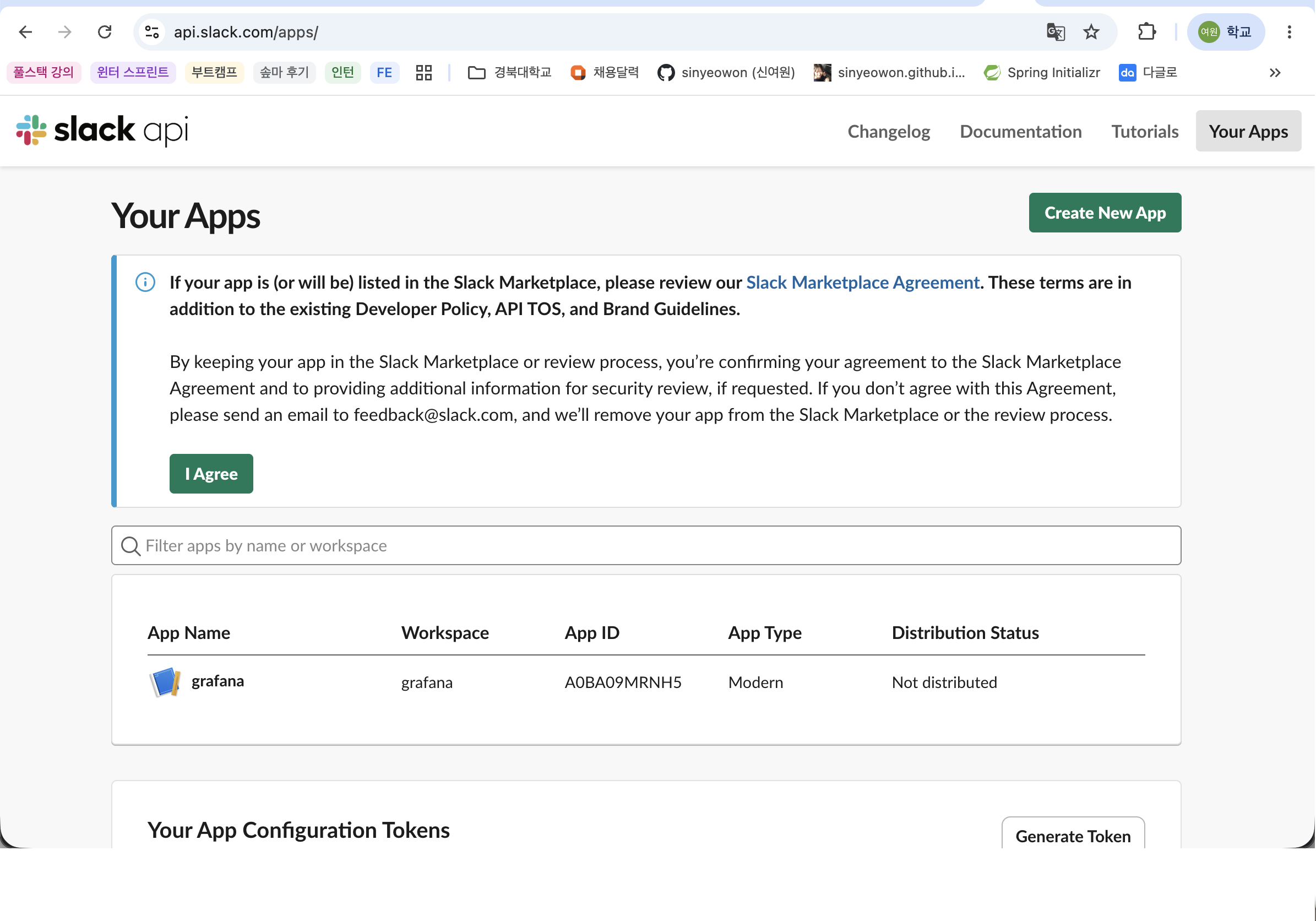
Webhook URL 생성 화면
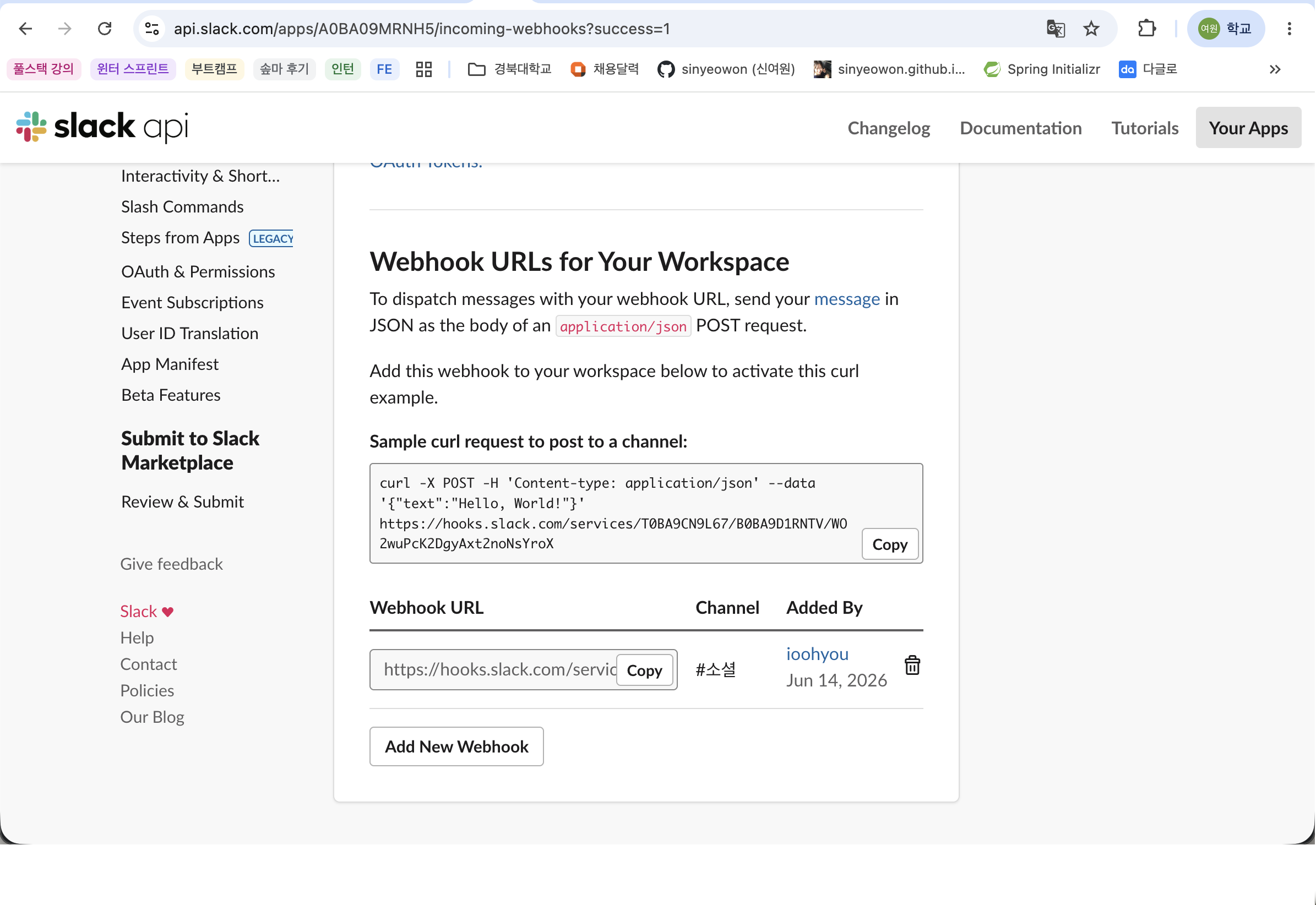
Grafana Contact point 설정 화면
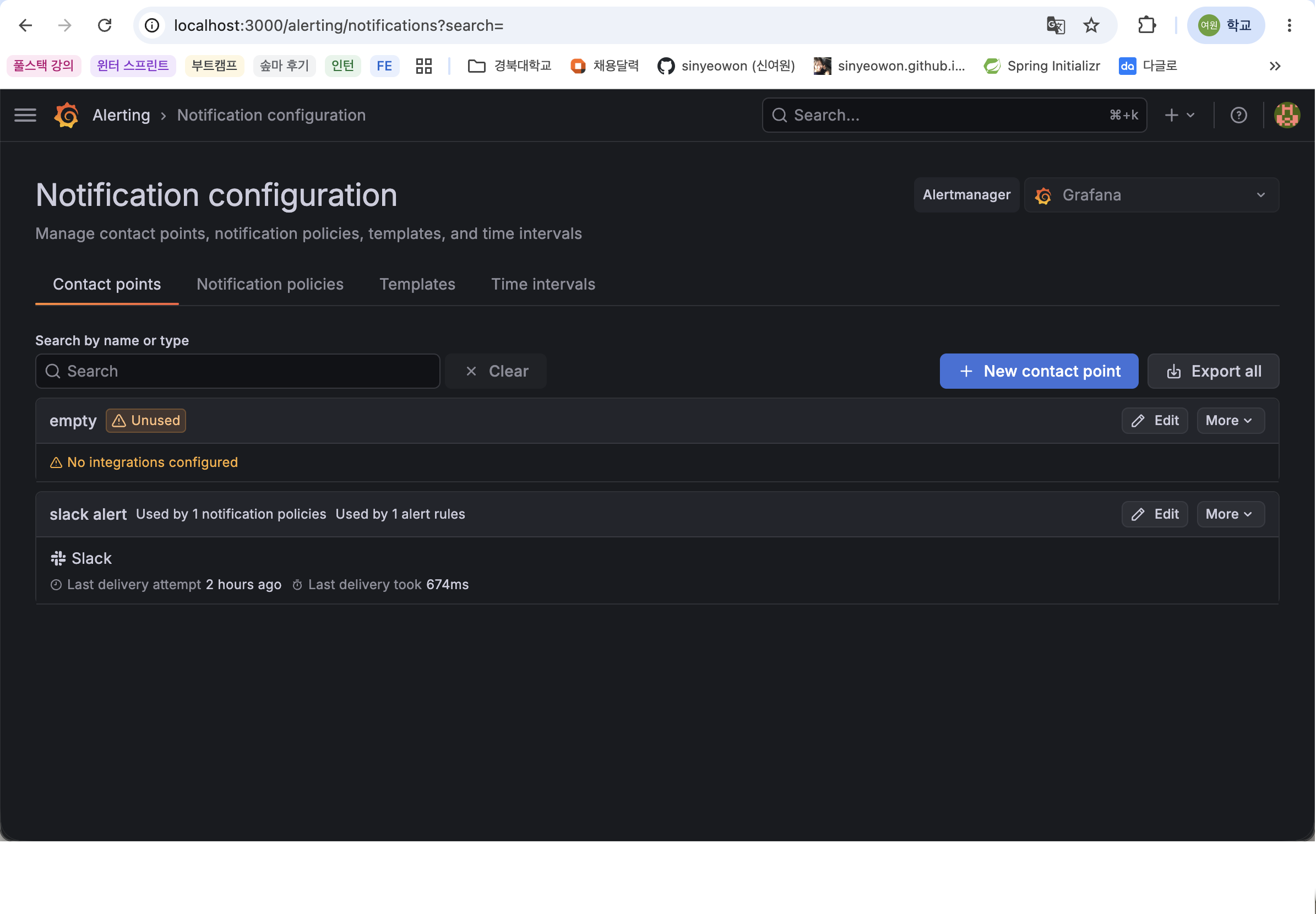
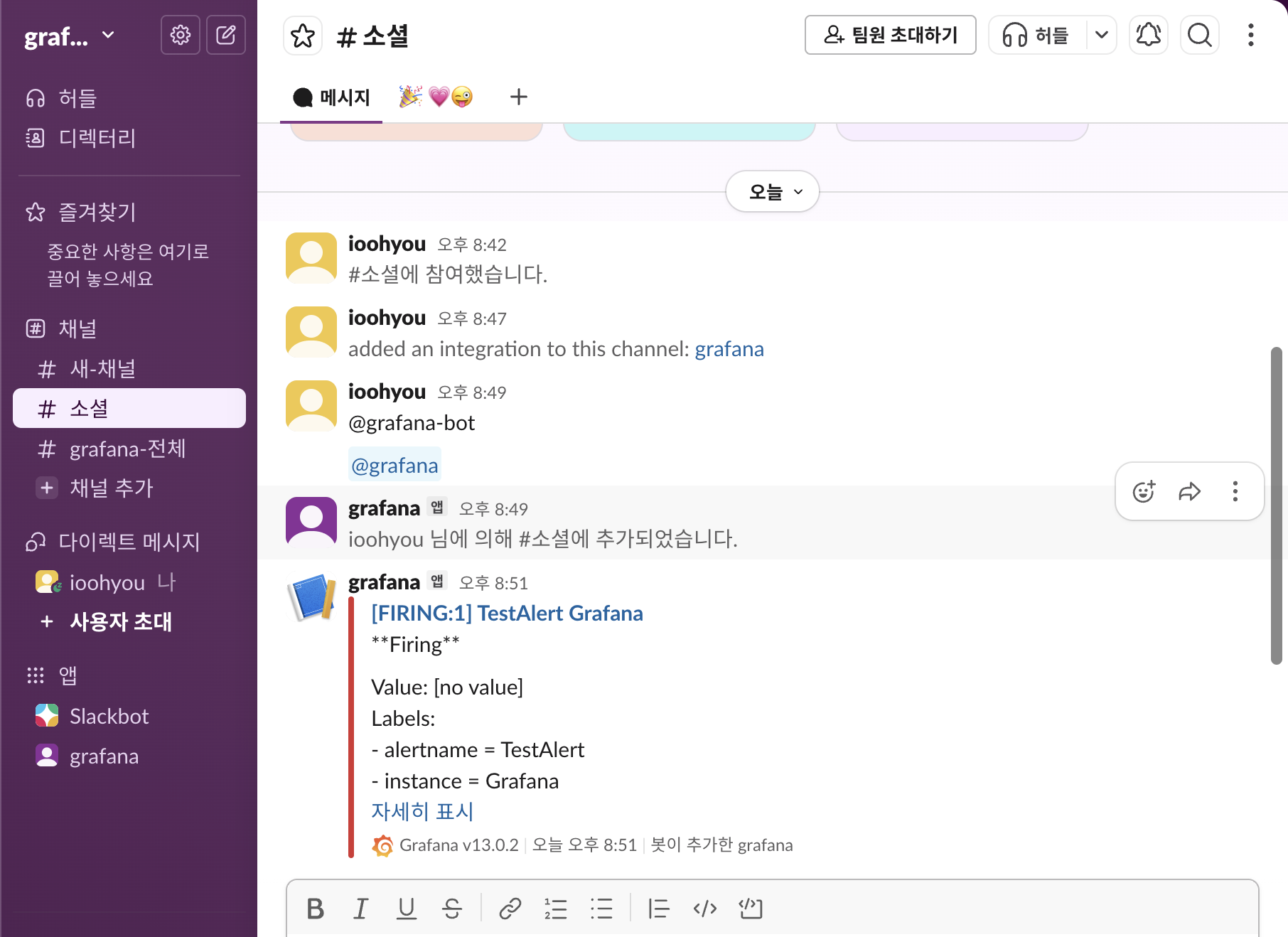
Slack 테스트 메시지 수신 화면
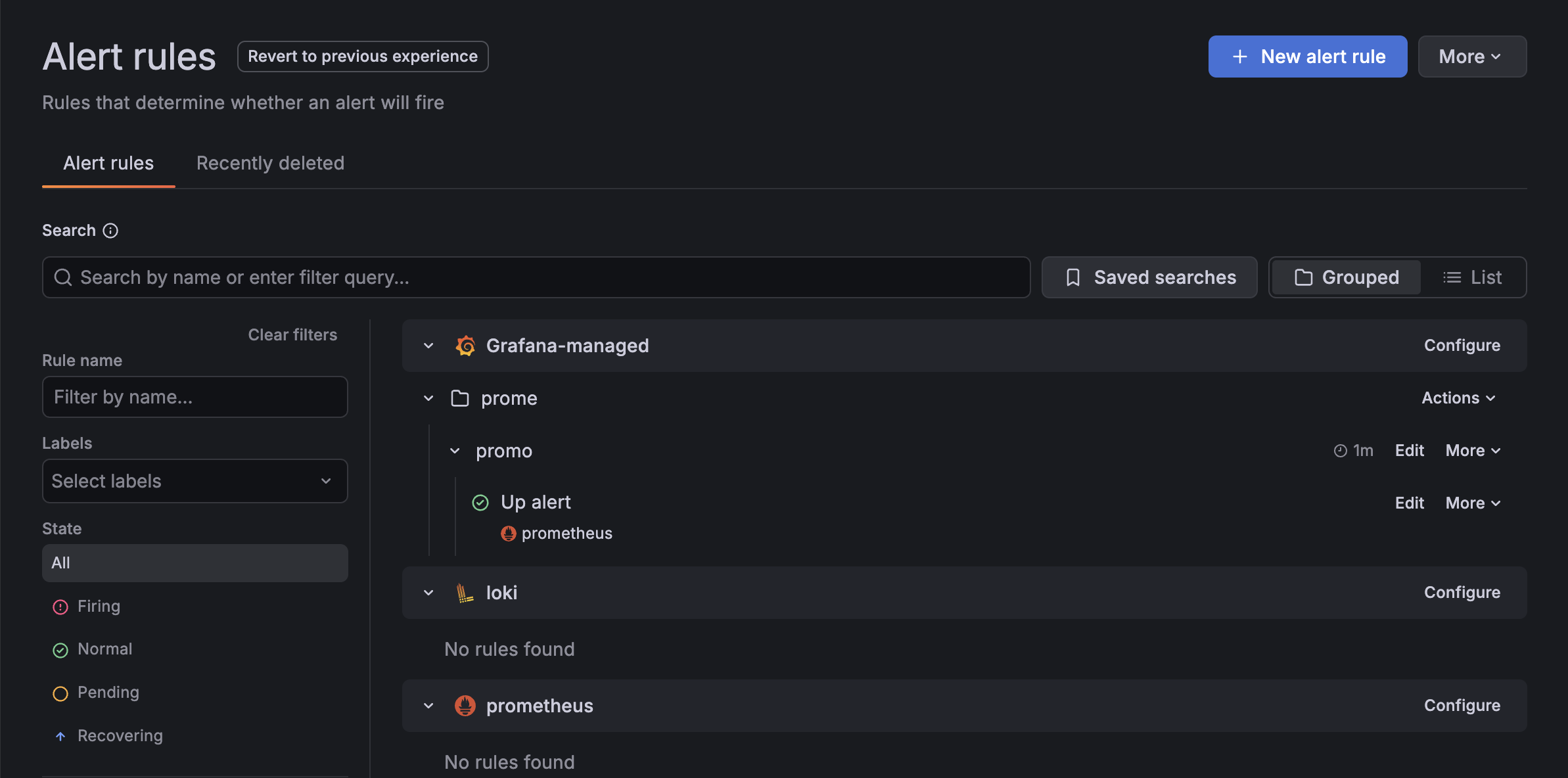
Alert Rule 설정
Grafana에서 Alert rule을 생성한다.
조건은 다음과 같이 설정했다.
1
up{job="spring-boot"}
Threshold 조건은 다음과 같이 설정한다.
1
IS BELOW 1
이 조건은 up{job="spring-boot"} 값이 1보다 작을 때 Alert를 발생시킨다는 의미이다.
Prometheus에서 up 값은 타겟이 정상적으로 수집되면 1, 수집되지 않으면 0으로 표시된다.
따라서 Spring Boot 애플리케이션이 정상 실행 중이면 up = 1, 애플리케이션이 중지되면 up = 0이 되어 Alert 조건에 걸린다.
Evaluation 설정
빠른 확인을 위해 Evaluation interval과 Pending period를 1분으로 설정했다.
1
2
Evaluation interval: 1m
Pending period: 1m
이 설정은 Grafana가 1분마다 조건을 평가하고, 조건이 1분 동안 유지되면 Firing 상태로 변경한다는 의미이다.
즉, 애플리케이션을 정지하자마자 바로 Slack 알림이 오는 것이 아니라, 일정 시간 동안 조건이 유지되어야 알림이 발생한다.
Alert 상태 변화
Alert rule을 저장한 뒤 Spring Boot 애플리케이션을 중지하면 상태가 다음과 같이 변경된다.
1
Normal → Pending → Firing
이후 Slack으로 Firing 알림이 전송된다.
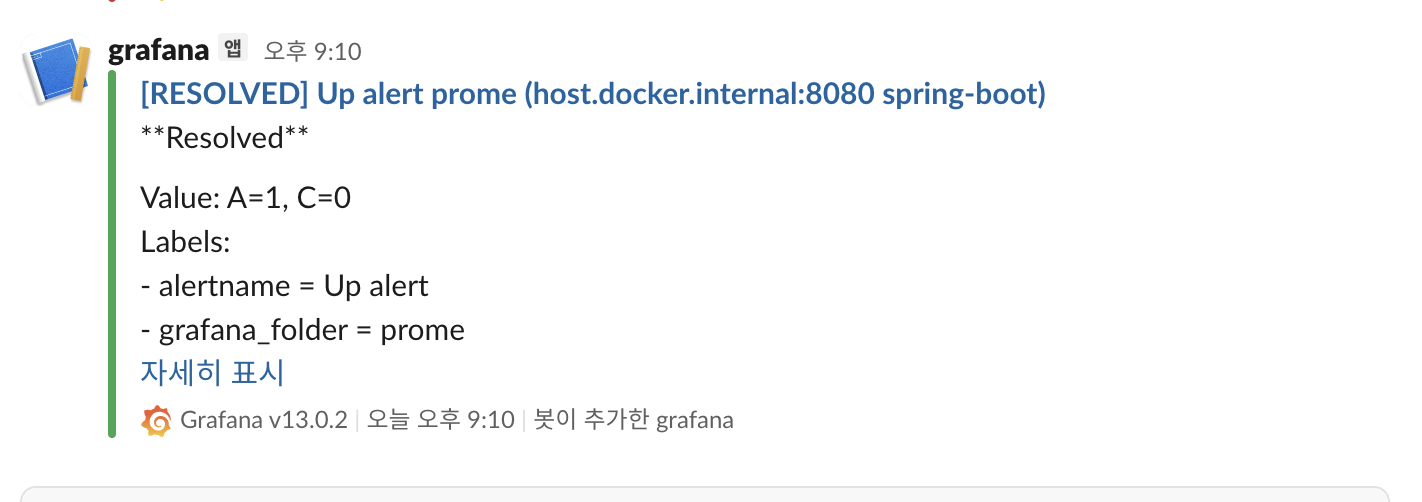
다시 Spring Boot 애플리케이션을 실행하면 상태가 정상으로 돌아오고, 잠시 후 Resolved 알림이 Slack으로 전송된다.
1
Firing → Normal
Alert rule 생성,
up{job="spring-boot"}쿼리 설정 화면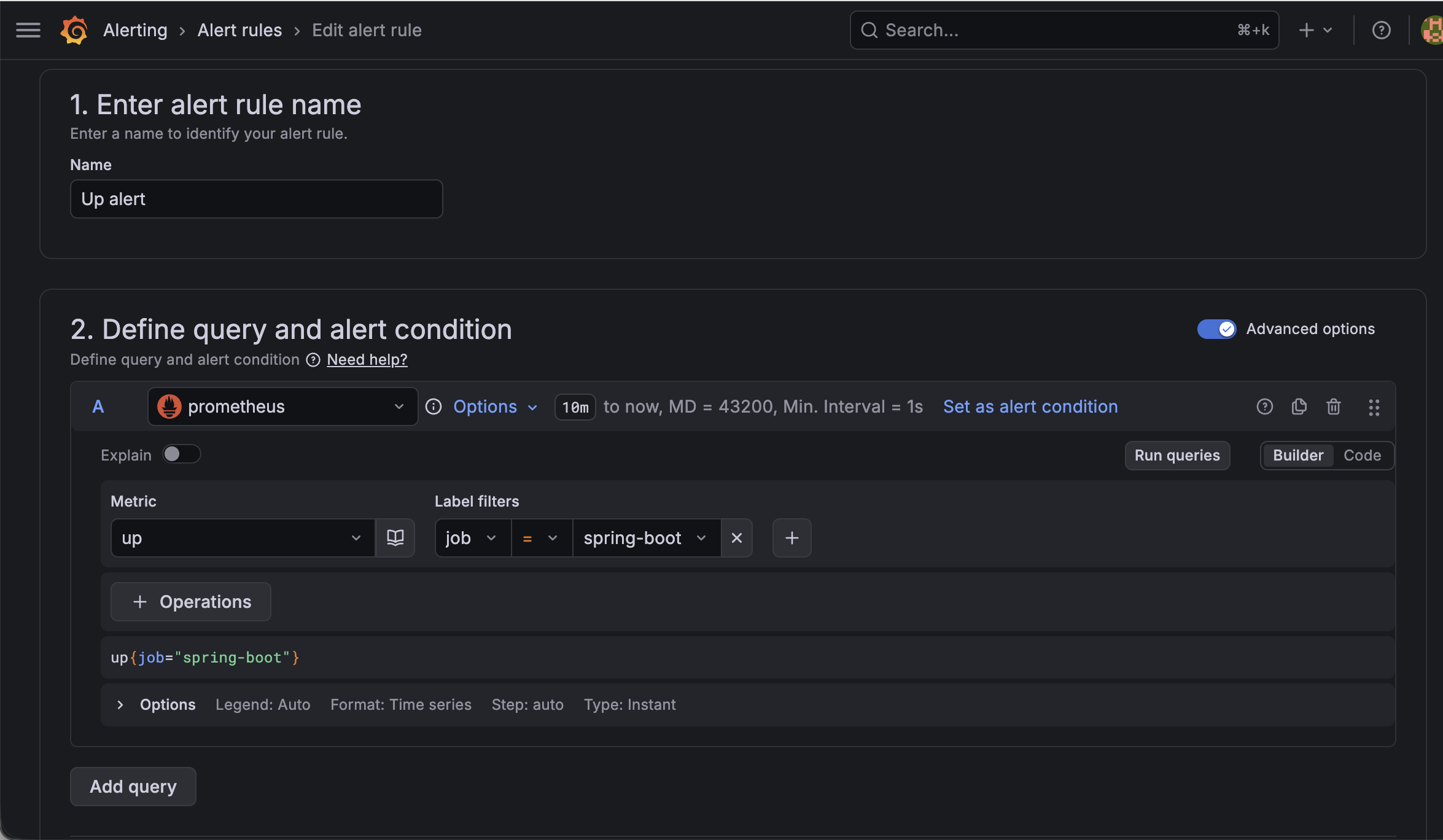
Threshold
IS BELOW 1설정 화면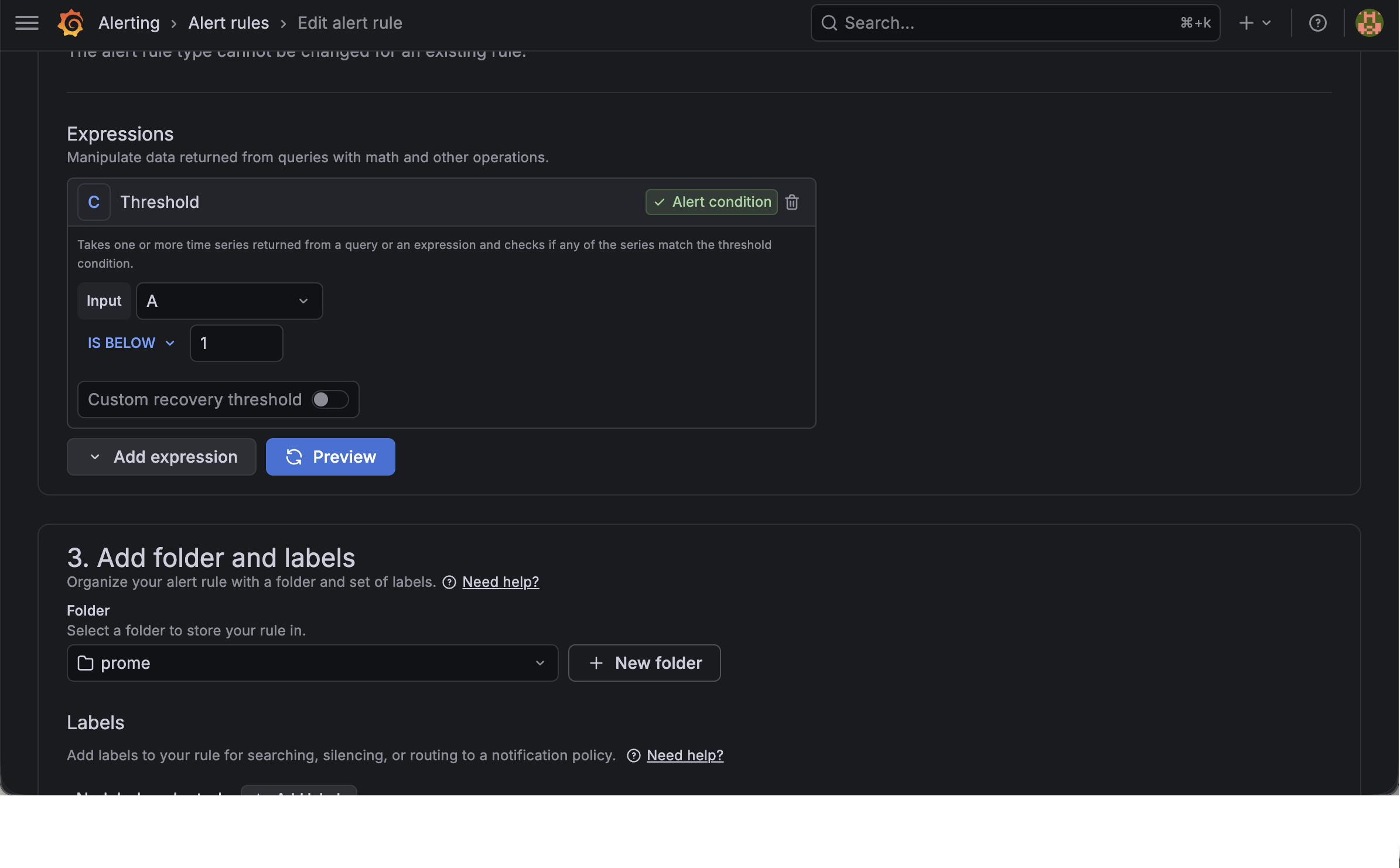
Evaluation interval, Pending period 설정 화면
Alert 상태가 Normal인 화면
Spring Boot 정지 후 Pending 또는 Firing 상태 화면

Slack Firing 알림 수신 화면
Spring Boot 재실행 후 Resolved 알림 수신 화면
Loki를 이용한 애플리케이션 로그 모니터링
Loki란?
Loki는 Grafana Labs에서 개발한 로그 수집 및 조회 시스템이다.
Prometheus가 메트릭을 수집한다면, Loki는 애플리케이션 로그를 수집한다.
Grafana와 함께 사용하면 메트릭뿐만 아니라 로그까지 한 화면에서 조회할 수 있다.
Loki가 필요한 이유
장애가 발생했을 때 메트릭만으로는 원인을 정확히 알기 어렵다.
예를 들어 서버가 내려갔거나 에러가 증가했다는 사실은 Prometheus와 Grafana로 확인할 수 있지만, 왜 에러가 발생했는지는 로그를 봐야 알 수 있다.
Loki를 사용하면 애플리케이션 로그를 Grafana에서 직접 조회할 수 있기 때문에 장애 원인 분석이 더 쉬워진다.
즉, Prometheus와 Grafana가 “무슨 일이 발생했는지” 보여준다면, Loki는 “왜 그런 일이 발생했는지” 확인하는 데 도움을 준다.
Spring Boot 로그 전송 설정
Spring Boot 애플리케이션에서 Loki로 로그를 보내기 위해 loki-logback-appender 의존성을 추가한다.
1
2
3
4
5
6
dependencies {
implementation 'com.github.loki4j:loki-logback-appender:1.5.1'
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'org.springframework.boot:spring-boot-starter-web'
runtimeOnly 'io.micrometer:micrometer-registry-prometheus'
}
테스트를 위해 루트 경로에 접근하면 403 에러와 로그가 발생하도록 컨트롤러를 작성한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import jakarta.servlet.http.HttpServletResponse;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@RestController
public class SampleController {
private static final Logger logger = LoggerFactory.getLogger(SampleController.class);
@GetMapping("/")
public String hello(HttpServletResponse response) throws IOException {
logger.info("Attempted access to / endpoint resulted in 403 Forbidden");
response.sendError(HttpServletResponse.SC_FORBIDDEN, "Access Denied");
return null;
}
}
resources/logback.xml 파일을 생성하여 로그가 Loki로 전송되도록 설정한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<configuration>
<appender name="LOKI" class="com.github.loki4j.logback.Loki4jAppender">
<http>
<url>http://localhost:3100/loki/api/v1/push</url>
</http>
<format>
<label>
<pattern>app=my-app,host=${HOSTNAME}</pattern>
</label>
<message class="com.github.loki4j.logback.JsonLayout" />
</format>
</appender>
<root level="DEBUG">
<appender-ref ref="LOKI" />
</root>
</configuration>
Loki 실행
Loki 설정 파일인 loki-config.yml을 생성한 뒤 Docker로 Loki를 실행한다.
1
2
3
4
5
6
docker run --name loki -d \
- v /path/to/loki-config.yml:/mnt/config/loki-config.yml \
- p 3100:3100 \
grafana/loki:3.0.0 \
- config.file=/mnt/config/loki-config.yml
실행 후 다음 주소로 접속하여 Loki가 정상 실행 중인지 확인한다.
1
http://localhost:3100/ready
정상 실행 중이면 ready가 출력된다.
localhost:3100/ready접속 결과 화면
Grafana에서 Loki Data source 추가
Grafana에서 Loki 로그를 조회하려면 Loki를 Data source로 추가해야 한다.
설정 순서는 다음과 같다.
Grafana Data sources 메뉴 이동
Add new data source 클릭
Loki 선택
Loki URL 입력
Save & test 클릭
Docker 환경에서 Grafana가 Loki에 접근하도록 다음 주소를 입력한다.
1
http://host.docker.internal:3100
Grafana Explore에서 로그 확인
Spring Boot 애플리케이션의 루트 페이지에 접근하여 403 에러를 발생시킨다.
1
http://localhost:8080
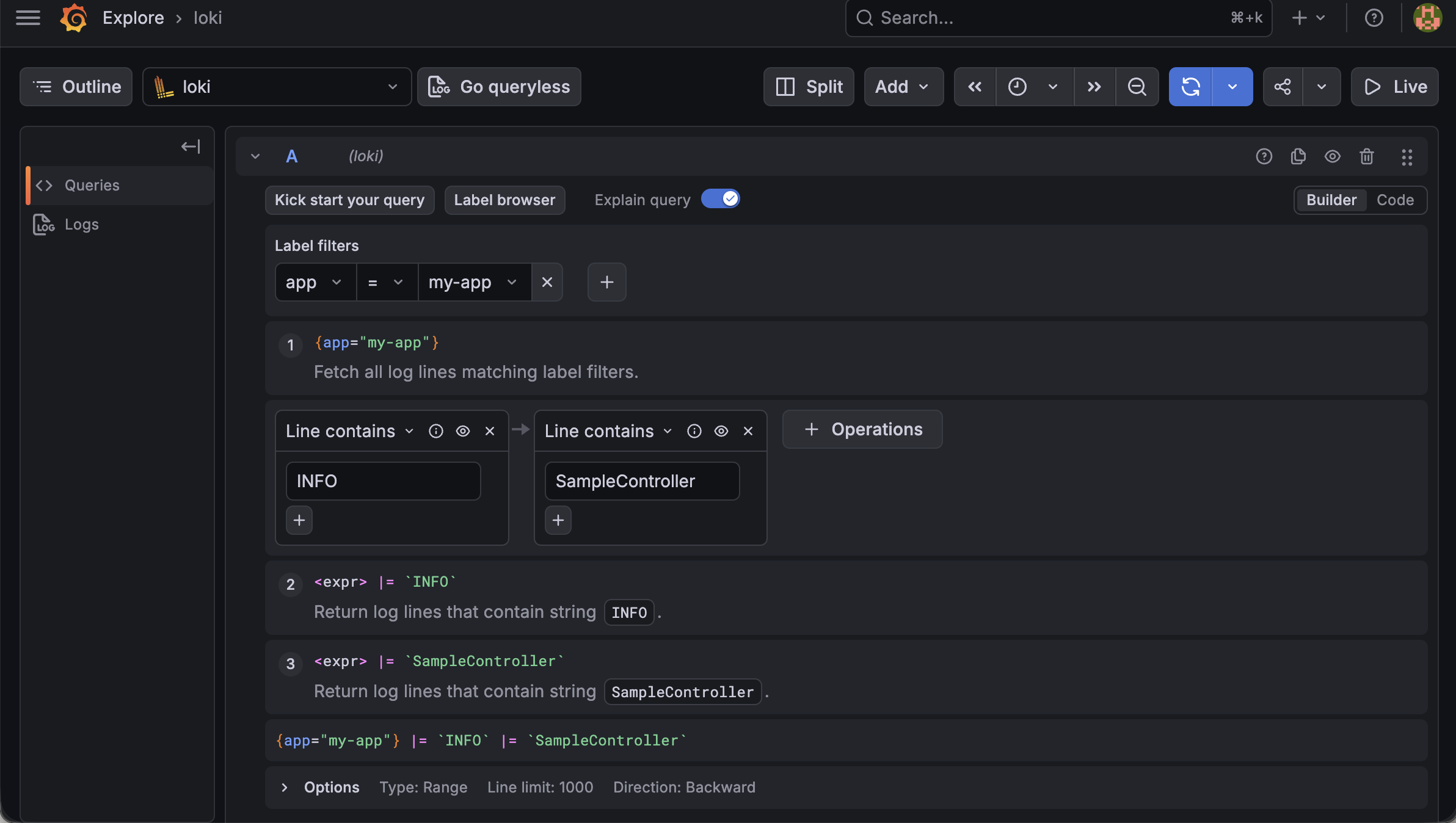
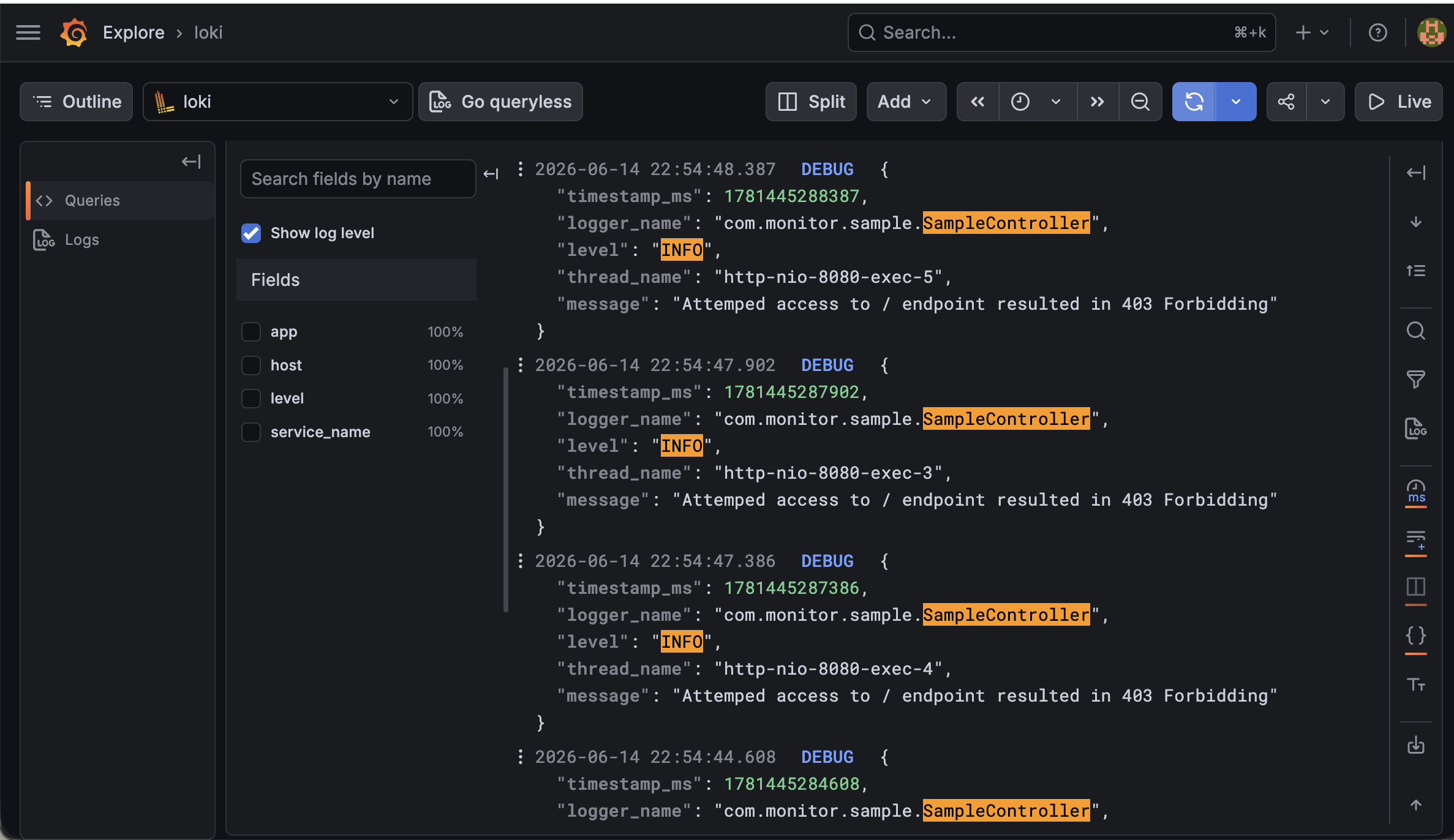
이후 Grafana에서 Explore 메뉴로 이동한 뒤 Loki를 선택하고 로그 쿼리를 실행한다.
예시 쿼리는 다음과 같다.
1
{app="my-app"}
쿼리를 실행하면 Spring Boot 애플리케이션에서 발생한 로그를 Grafana에서 확인할 수 있다.
루트 페이지 접속 시 403 에러 화면
Grafana Explore에서 Loki 로그 조회 화면
전체 흐름 정리
이번 실습의 전체 흐름은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Spring Boot Actuator
→ 애플리케이션 상태와 메트릭 노출
Prometheus
→ Actuator의 Prometheus 메트릭을 주기적으로 수집
Grafana
→ Prometheus 데이터를 시각화
Grafana Alert + Slack
→ 애플리케이션 장애 발생 시 Slack 알림 전송
Loki
→ 애플리케이션 로그 수집 및 Grafana에서 조회
정리하면, Actuator는 애플리케이션의 상태를 외부에 제공하고, Prometheus는 그 데이터를 수집하고, Grafana는 시각화하며, Slack Alert는 장애를 알려주고, Loki는 장애 원인 분석을 위한 로그를 제공한다.
실습 중 헷갈렸던 점
Slack 알림이 바로 오지 않았던 문제
Alert rule을 설정한 뒤 Spring Boot 애플리케이션을 정지했지만 Slack 알림이 바로 오지 않았다.
이때 Evaluation interval과 Pending period가 각각 1분으로 설정되어 있어, 조건이 만족되더라도 바로 Firing 상태가 되는 것이 아니라 일정 시간 동안 조건이 유지되어야 알림이 발생한다는 점을 알게 되었다.
또한 Alert rule을 생성한 뒤 반드시 저장해야 하고, Contact point 테스트를 통해 Slack Webhook이 정상 동작하는지도 확인해야 한다.
up{job="spring-boot"}** **값의 의미
처음에는 up 메트릭이 정확히 무엇을 의미하는지 헷갈렸다.
up{job="spring-boot"} 값이 1이면 Prometheus가 Spring Boot 애플리케이션의 메트릭을 정상적으로 수집하고 있다는 의미이고, 0이면 수집에 실패했다는 의미이다.
따라서 애플리케이션이 정지되었을 때 up < 1 조건을 사용하면 장애 상황을 감지할 수 있다.
배운 점 및 회고
이번 실습을 통해 모니터링이 단순히 “서버가 켜져 있는지 확인하는 것”이 아니라, 애플리케이션 운영에 필요한 상태 정보, 메트릭, 로그, 알림을 함께 구성하는 과정이라는 것을 알게 되었다.
특히 Actuator, Prometheus, Grafana의 역할이 처음에는 비슷하게 느껴졌지만, 실습을 진행하면서 각각의 책임이 다르다는 것을 이해할 수 있었다.
Actuator는 Spring Boot 애플리케이션의 상태와 메트릭을 외부로 노출하고, Prometheus는 그 메트릭을 주기적으로 수집하고 저장한다. Grafana는 Prometheus 데이터를 시각화하여 사람이 보기 쉽게 만들어주며, Alert 기능을 통해 장애 상황을 Slack으로 알릴 수 있다. Loki는 애플리케이션 로그를 수집하여 장애가 발생했을 때 원인을 분석하는 데 도움을 준다.
이번 실습에서 가장 인상 깊었던 부분은 Slack Alert였다.
대시보드를 직접 보고 있지 않아도 애플리케이션이 중지되면 Slack으로 알림을 받을 수 있다는 점이 실제 운영 환경과 연결되어 있다고 느껴졌다. 단순히 코드를 작성하는 것에서 끝나는 것이 아니라, 서비스가 죽었을 때 어떻게 알아차리고 대응할 것인지까지 고려해야 한다는 점을 배웠다.
또한 Grafana 버전에 따라 UI가 달라 강의와 같은 버튼이 보이지 않거나, Alert 설정 후 바로 알림이 오지 않는 등 예상과 다른 상황도 있었다. 이 과정에서 단순히 강의 화면을 따라가는 것이 아니라, 현재 설정값과 도구의 동작 방식을 이해하면서 문제를 해결해야 한다는 것을 느꼈다.
결론적으로 이번 학습을 통해 Spring Boot 애플리케이션을 운영 관점에서 바라보는 경험을 할 수 있었다. 앞으로 프로젝트를 진행할 때도 기능 구현뿐만 아니라 상태 확인, 장애 감지, 로그 분석까지 고려하는 백엔드 개발자가 되어야겠다고 느꼈다.
댓글
궁금한 점, 피드백, 오류 제보를 남겨 주세요.