[TIL] MSA 데이터 정합성 특강
MSA 분산 트랜잭션 및 데이터 정합성 문제, Saga 패턴, 보상 트랜잭션, Outbox 패턴의 개념
For the English version of this post, see here.
배운 내용
1. 분산 트랜잭션의 복잡성
(1) 모놀리식에서의 트랜잭션 vs 마이크로서비스에서의 문제
Multiple Microservices에서는 예시로 주문(Order), 인보이스(Invoice), 결제(Payment), 배송(Shipping) 등이 각기 다른 서비스와 DB로 구성되어 협업한다.
- 모놀리식 애플리케이션의 경우
하나의 데이터베이스만 접근하므로, Spring 등 프레임워크가 제공하는 선언적 트랜잭션(@Transactional 등)을 사용해 간단히 트랜잭션을 관리할 수 있음
모든 데이터가 한 군데에 있으니 커밋/롤백 로직이 단순함
- 마이크로서비스 환경의 경우
각각의 서비스가 별도의 DB나 메시지 브로커 등을 사용하므로, 하나의 비즈니스 로직에도 여러 서비스가 연계됨
전통적인 분산 트랜잭션(2PC 등)을 적용하려면 여러 제약이 따름
- 많은 NoSQL DB나 Kafka, RabbitMQ 등 최신 기술은 XA 같은 2PC 트랜잭션을 지원하지 않음
(2) 2PC/XA 프로토콜 한계
- XA 프로토콜(2PC)을 이용한 전통적 분산 트랜잭션
이론적으로는 여러 자원을 동시에 커밋/롤백 가능하나, 최신 NoSQL 메시지 브로커가 지원하지 않는 경우가 많으며, 이종(heterogeneous) 환경에서는 적용이 어려움
참여 노드가 모두 ‘항상 가용’해야 하므로, 시스템 전체 가용성을 떨어뜨리는 요인이 됨
→ 결과적으로 마이크로서비스 환경에서는 분산 트랜잭션을 쉽게 처리하기가 어려우며, Saga 패턴 같은 대안적 접근이 널리 쓰이게 되었다.
2. Sage 패턴의 개념과 필요성
(1) 왜 Saga가 해결책인가?
- 분산 트랜잭션의 대안
- 전통적 2PC가 적용 곤란한 마이크로서비스 환경에서, 각 서비스가 로컬 트랜잭션만 책임지고, 단계별 성공/실패 시 이벤트 혹은 지휘(Orchestrator)를 통해 전체 흐름을 제어하는 방식
- 로컬 트랜잭션 + 보상 트랜잭션
- 한 단계가 커밋된 뒤 다음 단계로 넘어가는 시점에서 장애가 발생하면, 이미 커밋된 작업을 ‘되돌리는(보상)’ 로직으로 정합성을 맞춤
(2) Saga의 작동 원리: 단계별 로컬 트랜잭션과 보상(Compensating) 트랜잭션
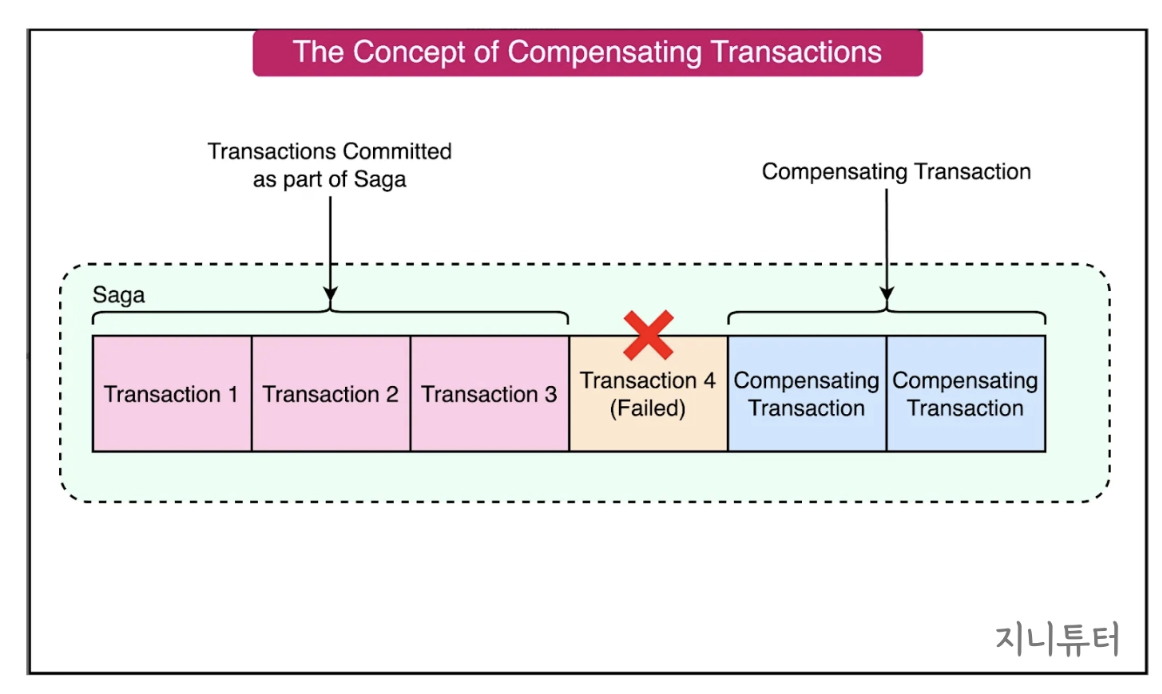 어떤 단계(T4)에서 실패가 발생하면, 이미 완료된 T1, T2, T3의 작업을 역순으로 취소(Undo)해야 함을 보여주는 그림
어떤 단계(T4)에서 실패가 발생하면, 이미 완료된 T1, T2, T3의 작업을 역순으로 취소(Undo)해야 함을 보여주는 그림
예) 전자상거래 주문 과정에서, 재고 감소 → 결제가 끝난 시점에 마지막 승인(Authorize)에서 실패하면, “재고 복원”하는 보상 트랜잭션을 수행
(3) 전자상거래 주문 예시, ACID와의 차이점 (고립성 이슈)
주문하기(Placing an Order) → 인보이스 생성(Creating an Invoice) → 결제 처리(Payment) → 배송(Shipping)
모놀리식에선 한 DB에서 트랜잭션으로 쉽게 처리했지만, 마이크로서비스로 분리되면 여러 DB/서비스 연계가 필요
전통적 ACID 트랜잭션은 ‘Isolation(고립성)’을 보장하지만, Saga에선 각 단계가 커밋되므로 중간 상태가 외부에 노출될 수 있음
3. 오케스트레이션 기반 Saga
(1) 중앙 집중형 Orchestrator와 Command/Reply
오케스트레이션 기반 Saga에서는 중앙에 Orchestrator가 존재하여 모든 로컬 트랜잭션의 순서(흐름)를 지휘한다. 오케스트레이터가 각 서비스에 “이제 결제해”, “이제 배송해” 같은 명령(Command) 메시지를 보내고, 서비스는 작업 완료 후 응답(Reply) 이벤트를 되돌려주는 구조이다.
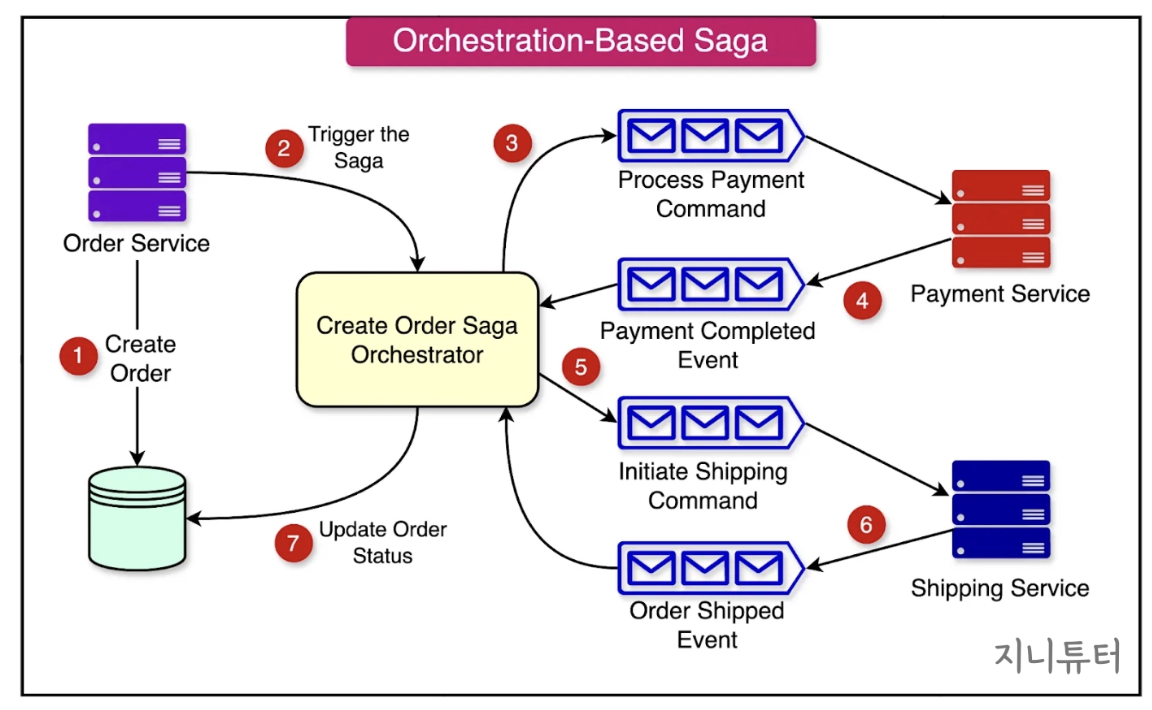
주문(Order Service)가 생성되면(1), 중앙의 Saga 오케스트레이터가 이를 받아들여 “결제 처리”를 지시(3)
결제 완료 이벤트(4)를 받으면 “배송”을 지시(5)
배송 완료(6)를 확인 후 주문 상태 최종 업데이트(7)
도중에 에러가 발생하면, 오케스트레이터가 보상 트랜잭션을 트리거하여 이미 커밋된 내용을 되돌림
(2) 오케스트레이션 기반의 장점과 단점
- 장점
- 간단해지는 의존관계 (Simpler Dependencies)
- 모든 흐름을 Orchestrator가 관리 → 순환 의존이 없음
- 느슨한 결합 (Loose Coupling)
- 각 서비스는 Orchestrator가 주는 Command에만 반응하면 되므로, 서비스 간 직접적 호출이 줄어듦
- 관심사의 분리 강화
- 전체 비즈니스 로직(흐름 제어)은 Orchestrator에 모이고, 각 서비스는 로컬 트랜잭션에 집중
- 간단해지는 의존관계 (Simpler Dependencies)
- 단점
- 비즈니스 로직의 중앙 집중화
Orchestrator에 과도한 로직이 쏠리면 “지나치게 스마트한” 중앙 시스템이 되고, 각 서비스는 단순해질 위험
단일 장애점(SPoF: Single Point of Failure)이 될 수 있으므로 HA(High Availability) 구성을 고려해야 함
Orchestrator가 모든 과정을 지휘하기 때문에 서비스가 다 멀쩡해도 Orchestrator가 죽으면 주문 처리가 아예 시작도 못 함
HA → 고가용성, 하나 죽어도 다른 애가 대신 일하게 만드는 구조
- 예를 들면 Orchestrator를 1개만 두는 게 아니라 여러 개 띄워둠
- 성능 이슈
- 모든 요청이 Orchestrator를 경유하므로 레이턴시가 추가되고, Throughput 한계가 Orchestrator 성능에 좌우됨
주문 서비스 → Orchestrator → 결제 서비스처럼 한 번 더 거치게 되므로, 중간 경우 시간이 추가되어 레이턴시가 증가함요청이 많이 들어오면 Orchestrator 하나가 다 조율하기 때문에 처리가 밀려 병목이 될 수 있음
- 전체 처리량이 Orchestrator 성능에 묶일 수 있음
- 모든 요청이 Orchestrator를 경유하므로 레이턴시가 추가되고, Throughput 한계가 Orchestrator 성능에 좌우됨
- 비즈니스 로직의 중앙 집중화
4. 코레오그래피 기반 Sage
(1) 이벤트 발행/구독 방식
코레오그래피 기반 Saga에서는 Orchestrator 없이, 각 서비스가 이벤트를 발행하고 구독(subscribe)하여 스스로 다음 단계를 진행한다.
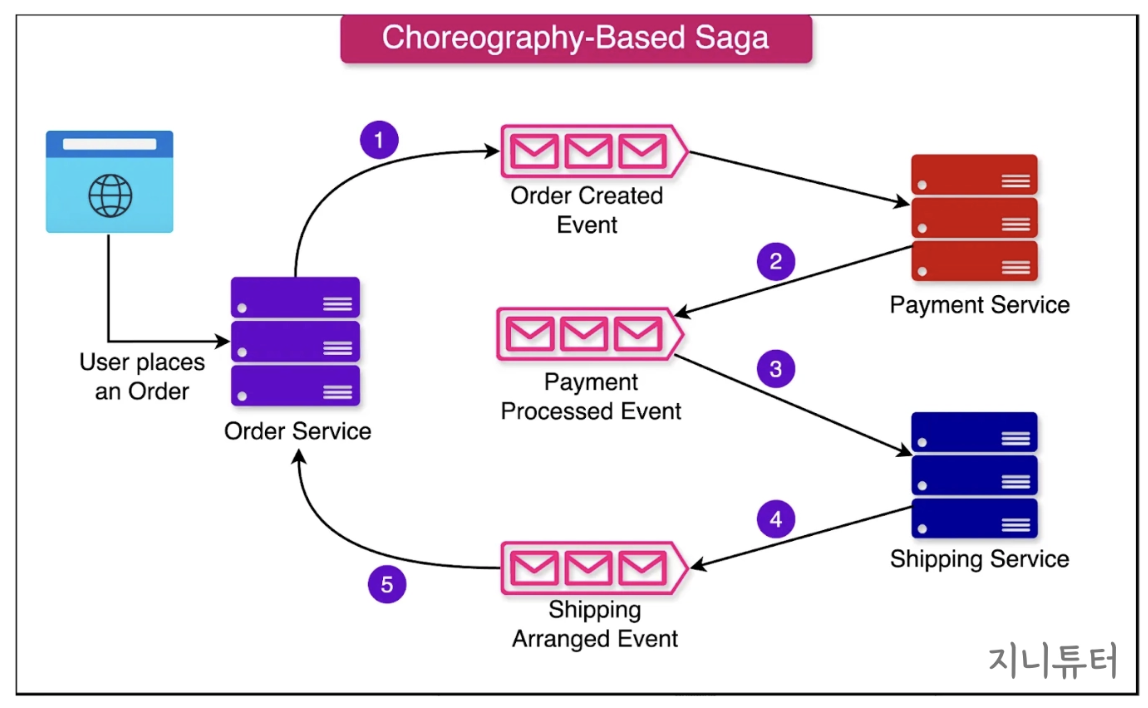
Order Service가
OrderCreated이벤트 발행Payment Service가 이를 구독 후 결제 진행, 성공 시
PaymentSucceeded이벤트 발행Shipping Service가 다시 이를 구독 후 배송 실행,
ShippingArranged이벤트 발행결제 실패 시 보상 트랜잭션으로 주문 취소 이벤트 등을 발행하여 흐름을 마무리
(2) OutBox 패턴 & 이벤트
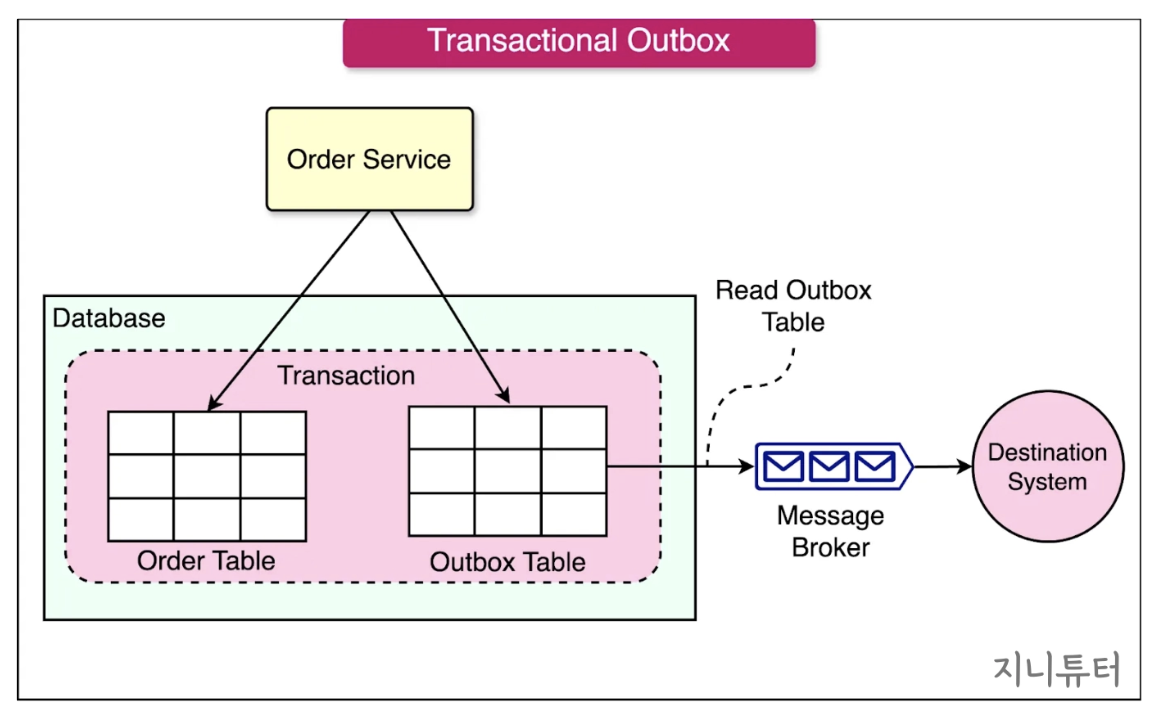
원자적(원자성) 보장: “DB 변경”과 “이벤트 발행”을 하나의 로컬 트랜잭션으로 묶기 위해 Outbox 테이블 기법을 사용 가능
- 예를 들어 주문 서비스가 주문을 만들면, DB에 주문 데이터를 저장하고, Kafka 같은 메시지 브로커에 이벤트도 보내야 함
문제는 이 둘이 따로따로 성공할 수도 있음 → 그러면 DB에는 주문이 있는데, 다른 서비스들은 ‘주문 생성됨’ 이벤트를 받지 못해서 주문이 생긴 줄 모르고, 배송 서비스는 배송을 안 만들 수도 있음
반대로도 가능 (Kafka 이벤트 발행 성공, DB 저장 실패) → 실제 DB에는 주문이 없는데, 다른 서비스들은 주문이 생겼다고 착각할 수 있음
- 그래서 OutBox 테이블 사용
이벤트 발행 예정 목록 테이블
바로 Kafka에 이벤트를 보내는 게 아니라, 먼저 내 DB 안에 이벤트 기록을 같이 저장함
→ 즉, DB 안에서 주문 저장과 이벤트 저장을 같이 처리함
- Kafka 발행은
- 나중에 별도의 프로세스가 outbox 테이블을 읽고 Kafka로 이벤트를 발행함 → 성공하면 outbox 상태를 (PENDING에서) SENT로 변경
이슈 2: NoSQL DB 같이 데이터베이스가 트랜잭션을 지원하지 않는 경우Transaction Outbox 패턴의 핵심은 엔터티 테이블과 Outbox 테이블의 원자성, 단일 트랜잭션을 보장하는 것인데,
주문 서비스가 NoSQL DB를 사용해서 트랜잭션을 지원하지 못하는 경우가 있을 수 있다.
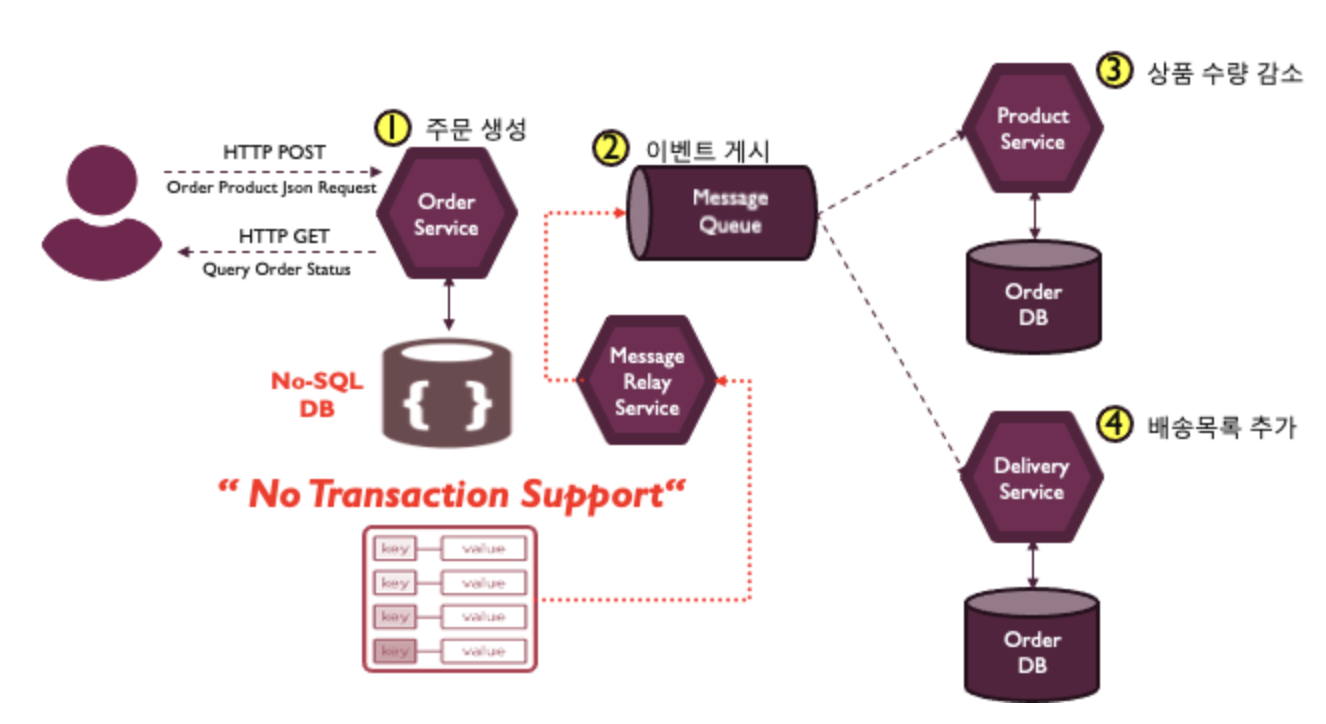
이런 경우 주문 정보가 담긴 객체에 메시지 내용을 포함하는 속성을 추가해서 메시지를 메시지 브로커에 전송하면 된다.
NoSQL DB에 발행할 이벤트 정보를 추가하는 것도 원자성을 갖고 있다고 할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
{ order_id: "20231108019", buyer: { id: 10003, email: "abcd@sk.com", address: "SK U Tower" }, item: { id: 13035, name: "Wireless Keyboard", quantity: 1 }, <span style="color: #ff0000">outbox: [...]</span> }메시지 릴레이 서비스가 주기적으로 데이터베이스내 레코드를 쿼리해서 아웃박스 속성을 찾아 메시지 브로커에 전달하고
마지막에 해당 레코드 내의 Outbox 애트리뷰트를 삭제하는 방식으로 트랜잭션을 지원하지 않는 NoSQL DB를 사용하더라도 트랜잭셔널 아웃박스 패턴을 사용할 수 있다.
- 예를 들어 주문 서비스가 주문을 만들면, DB에 주문 데이터를 저장하고, Kafka 같은 메시지 브로커에 이벤트도 보내야 함
Correlation IDs: 이벤트에
orderId등 공통 식별자를 포함해, 다른 서비스가 어떤 트랜잭션/주문과 연관된 이벤트인지 파악하도록 함추적용 공통 식별자
서비스들이 발생하는 이벤트가 같은 주문에서 나온 건지 확인하기 위해 사용함
예를 들어, 주문 흐름에서는 orderId가 Correlation Id처럼 쓰일 수 있음
이슈 1: 이벤트의 중복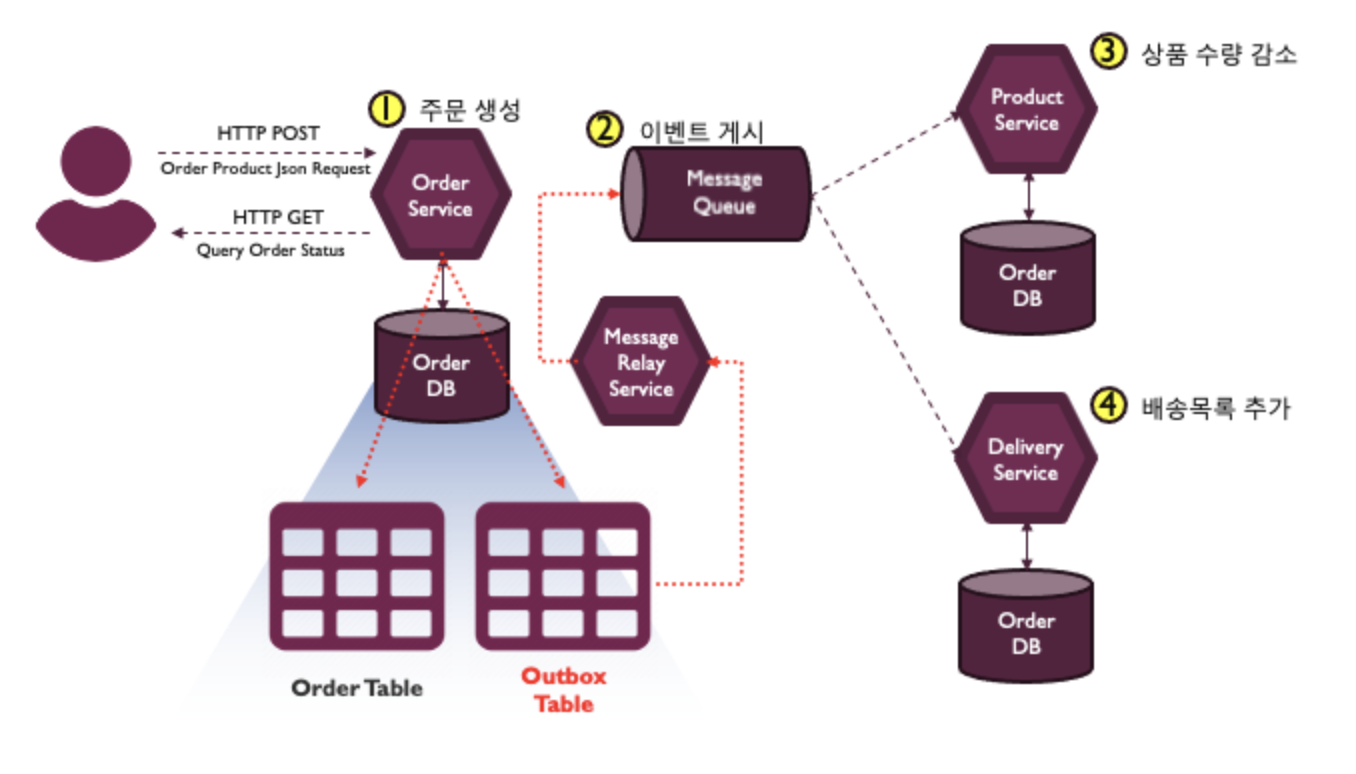
메시지 릴레이 서비스가 Outbox 테이블에서 메시지 데이터를 읽어서 메시지 브로커에 전달하다가 오류가 나는 경우,
다른 메시지 릴레이 서비스의 인스턴스가 Outbox 테이블에서 다시 메시지 브로커에 전달하는 경우 같은 메시지가 두번 전달되는 상황이 벌어져,
상품 수량을 두번 감속시키고 배송 목록을 두 개 만드는 문제가 발생한다.
→ 이 문제는 상품 서비스와 배송 서비스가 멱등성을 보장하도록 개발하면 해결할 수 있다. (같은 요청을 여러 번 보내도 결과가 똑같이 유지되는 성질)
Outbox 테이블이 메시지 정보를 저장할때 각 메시지마다 ID값을 할당하고, 메시지 릴레이 서비스가 메시지 브로커로 발생하는 이벤트에 해당 아이디 값을 부여하면,
메시지를 수신한 상품, 배송 서비스는 이 아이디값을 비교해서 이미 처리된 이벤트, 중복 이벤트라는 것을 알고 무시 할 수 있다.
이슈 3: 메시지 순서만약 사용자가 상품을 주문하자 마자 바로 취소하는 경우, 메시리 릴레이 서비스가 주기적으로 아웃박스 테이블을 모니터링하다가 주문 생성, 주문 취소의 두개의 메시지를 찾았는데,
비즈니스의 순서를 이해하지 못하고 주문 취소 이벤트를 주문 생성 이벤트보다 먼저 발행할 수 있다.
이런 경우, 배송서비스는 주문 취소 이벤트를 수신해서 이미 추가된 배송정보를 삭제해야 하는데 정보가 없어서 무시하게 되고 이후 주문 이벤트를 수신해서 배송 정보를 생성하게 되면,
주문은 취소되었지만 배송 목록에는 남아 있는 문제가 발생할 수 있다.
이 문제는 아웃박스 테이블이 메시지 마다 시퀀셜한 아이디를 부여해서, 이벤트를 발행할때 아이디로 정렬해서 순서를 맞춰서 해결할 수 있다.
(3) 코레오그래피 장점/단점
- 장점
- SPOF(단일 장애점) 부재
- 중앙 Orchestrator가 없으므로 한 지점 장애로 전체가 멈추지 않음
- 확장성
- 이벤트 기반으로 서비스가 늘어나도, 구독만 추가하면 새 기능을 붙이기 상대적으로 쉬움
- SPOF(단일 장애점) 부재
- 단점
- 이벤트 플로우 분산
- 전체 비즈니스 로직이 여러 서비스 이벤트로 쪼개져 있어, 디버깅/관리 난이도가 상승.
- 이벤트 순서, 중복, 사이클
- 순서 보장, 같은 이벤트를 여러 번 처리하지 않도록 하는 로직, 순환 참조 등을 신중히 설계해야 함.
- 이벤트 플로우 분산
5. 오케스트레이션 vs 코레오그래피: Saga 관점에서의 비교
1
2
3
4
5
6
7
8
9
10
11
[오케스트레이션 기반 Saga]
1) 순서 제어 및 보상 트랜잭션을 중앙 Orchestrator가 담당
2) 서비스 간 결합도 낮음, 전체 흐름 한눈에 파악 쉬움
3) 단일 장애점(SPoF), Orchestrator 로직 과부하 위험
[코레오그래피 기반 Saga]
1) 이벤트 발행/구독으로 상호작용
2) 중앙 집중 구성이 없어 장애 전파 위험 감소, 유연성 높음
3) 이벤트 흐름이 복잡해지면 관리/디버깅 어려움
두 방식 모두 마이크로서비스 환경에서 Saga 패턴을 구현하는 대표적인 기법이며, 조직 문화나 시스템 규모에 따라 적절히 선택하거나 혼합해서 사용 가능하다.
6. 오케스트레이션 vs 코레오그래피: 마이크로서비스 협업 모델 전반에서의 적용
Saga를 넘어, 마이크로서비스들이 협업할 때 Orchestration과 Choreography라는 두 가지 접근을 전반적으로 비교한 내용 (마이크로서비스 트랜잭션 외에 일반적인 서비스 간 협업 패턴까지 포함)
(1) 전반적인 개요
- Orchestration(오케스트레이션)
중앙 Orchestrator가 모든 호출(Invoke)과 응답(Reply)을 중재
서비스 결합도가 낮고, 도메인 경계가 명확해 테스트 범위가 분명함
- Choreography(코레오그래피)
각 서비스가 직접 메시지를 주고받는 포인트 투 포인트 통신
서비스 의존이 얽혀 복잡, 장애 극복(페일오버) 시나리오도 까다로울 수 있음
(2) Netflix Conductor 등 실제 사례
- Netflix Conductor:
넷플릭스에서 오픈 소스로 공개한 마이크로서비스 오케스트레이션 툴
중앙에서 여러 마이크로서비스의 실행 흐름(워크플로우)을 정의/제어
이 외에도 Camunda, Zeebe, AWS Step Functions 등 다양한 Orchestrator 툴이 존재하며, 각각 성능/운영 편의성/장애 대응 방식 등에 차이가 있다.
예시 소스코드
Orchestration 기반 SAGA 패턴을 Spring Boot + Kafka로 간단히 시연하기 위한 샘플 코드입니다.
실제 운영 환경에서 MSA(마이크로서비스)로 구성하려면, 각 서비스(주문, 결제, 배송 등)를 별도 프로젝트나 별도 애플리케이션으로 분리하고, DB·레포지토리·구성 파일 등도 각각 나눠야 합니다.
여기서는 하나의 Spring Boot 애플리케이션 안에 간단히 모형화하여, SAGA(오케스트레이션) 흐름과 코드 구조가 어떻게 생겼는지 맛보기 용도로만 살펴보겠습니다.
실행 흐름 요약
사용자가 POST /orders?productName=AAA&quantity=2&price=10000 호출
OrderService: DB에 Order (상태= PAYMENT_PENDING) 저장 후 OrderCreatedEvent(orderId, amount)를 발행 → order-events 토픽.
(실무) PaymentService: order-events를 구독 → 결제 시도 → 성공/실패 이벤트(PaymentCompletedEvent, PaymentFailedEvent)를 payment-events 토픽에 발행.
(샘플) 여기서는 PaymentServiceSimulator로 임의로 simulatePayment(orderId)를 호출해 이벤트를 강제로 발행하는 식.
- OrderOrchestrator
PaymentCompletedEvent 수신 시 → OrderStatus = PAID → 배송 요청 이벤트( shipping-events ) 발행
PaymentFailedEvent 수신 시 → OrderStatus = PAYMENT_FAILED → CANCELLED
ShippingCompletedEvent 수신 시 → OrderStatus = COMPLETED
주의사항 : 아래 코드는 학습을 위해 최대한 간략화했으며, 모든 예외처리·트랜잭션·보안·테스트 코드 등을 생략했습니다. 실무에선 더 정교한 설계와 부가적인 설정이 들어가야하니 참고
프로젝트 구조
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
└─ src
├─ main
│ ├─ java
│ │ └─ com.example.sagasample
│ │ ├─ SagasampleApplication.java
│ │ ├─ config
│ │ │ ├─ KafkaConsumerConfig.java
│ │ │ └─ KafkaProducerConfig.java
│ │ ├─ controller
│ │ │ └─ OrderController.java
│ │ ├─ domain
│ │ │ ├─ Order.java
│ │ │ ├─ OrderStatus.java
│ │ │ └─ PaymentStatus.java
│ │ ├─ events
│ │ │ ├─ OrderCreatedEvent.java
│ │ │ ├─ PaymentCompletedEvent.java
│ │ │ ├─ PaymentFailedEvent.java
│ │ │ └─ ShippingCompletedEvent.java
│ │ ├─ repository
│ │ │ └─ OrderRepository.java
│ │ ├─ service
│ │ │ ├─ OrderOrchestrator.java
│ │ │ ├─ OrderService.java
│ │ │ └─ PaymentServiceSimulator.java
│ │ └─ ...
│ └─ resources
│ └─ application.yml
└─ test
└─ ...
`application.yml`
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
server:
port: 8080
spring:
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: saga-example-group
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring.json.trusted.packages: "*"
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
Kafka 프로듀서/컨슈머 설정 (간단 예시)
예시에서는 Spring Boot의 자동설정(Spring for Apache Kafka)을 최대한 활용하고 있어, 별도 설정이 많지 않습니다.
주의: 실제 운영에서는 토픽 생성 권한이나 파티션 개수 등에 대한 전략이 필요합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
package com.example.sagasample.config;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaTopicConfig {
// 필요한 토픽들을 미리 생성 (자동 생성 옵션이 꺼져 있는 환경이라면)
@Bean
public NewTopic orderTopic() {
return new NewTopic("order-events", 3, (short)1);
}
@Bean
public NewTopic paymentTopic() {
return new NewTopic("payment-events", 3, (short)1);
}
@Bean
public NewTopic shippingTopic() {
return new NewTopic("shipping-events", 3, (short)1);
}
}
package com.example.sagasample.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
@EnableKafka
@Configuration
public class KafkaConsumerConfig {
// 추가적인 Consumer 설정이 필요하다면 Bean 등록
}
package com.example.sagasample.config;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaProducerConfig {
// Producer에 대한 추가 Bean 설정이 필요한 경우
}
도메인 및 이벤트 클래스
3-1) Order 도메인 (엔티티)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
package com.example.sagasample.domain;
import javax.persistence.*;
@Entity
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String productName;
private int quantity;
private int price;
@Enumerated(EnumType.STRING)
private OrderStatus orderStatus;
public Order() { }
public Order(String productName, int quantity, int price) {
this.productName = productName;
this.quantity = quantity;
this.price = price;
this.orderStatus = OrderStatus.CREATED;// 최초 주문 생성 시점
}
// getter / setter ...
public void setOrderStatus(OrderStatus status) {
this.orderStatus = status;
}
// 기타 편의 메소드 ...
}
1
2
3
4
5
6
7
8
9
10
11
package com.example.sagasample.domain;
public enum OrderStatus {
CREATED,// 주문 생성됨
PAYMENT_PENDING,// 결제 진행 중
PAYMENT_FAILED,// 결제 실패
PAID,// 결제 완료
SHIPPING,// 배송 중
COMPLETED,// 배송 완료(주문 최종 완료)
CANCELLED// 주문 취소됨 (보상 트랜잭션)
}
3-2) 이벤트 객체 (Kafka 메시지 Payload)
OrderCreatedEvent: 주문 서비스 -> 결제 서비스에 “주문 생성됨”을 알리는 이벤트
PaymentCompletedEvent / PaymentFailedEvent: 결제 서비스 -> 주문/오케스트레이터로 결제 결과를 통지
ShippingCompletedEvent: 배송 완료 이벤트 (여기서는 간단히만 시뮬레이션)
1 2 3 4 5 6 7 8 9
package com.example.sagasample.events; public class PaymentCompletedEvent { private Long orderId; // 결제 후 필요한 데이터public PaymentCompletedEvent() {} public PaymentCompletedEvent(Long orderId) { this.orderId = orderId; } }
1 2 3 4 5 6 7 8 9 10 11 12
package com.example.sagasample.events; public class PaymentFailedEvent { private Long orderId; private String reason; public PaymentFailedEvent() {} public PaymentFailedEvent(Long orderId, String reason) { this.orderId = orderId; this.reason = reason; } }
1 2 3 4 5 6 7 8 9 10 11
package com.example.sagasample.events; public class ShippingCompletedEvent { private Long orderId; public ShippingCompletedEvent() {} public ShippingCompletedEvent(Long orderId) { this.orderId = orderId; } // getter, setter }
레포지토리
1
2
3
4
5
6
7
package com.example.sagasample.repository;
import com.example.sagasample.domain.Order;
import org.springframework.data.jpa.repository.JpaRepository;
public interface OrderRepository extends JpaRepository<Order, Long> {
}
오케스트레이터(Orchestrator) & 서비스
5-1) OrderService
주문 생성 시 DB에
Order엔티티를 저장하고, 상태를PAYMENT_PENDING으로 변경한 뒤 OrderCreatedEvent 발행결제/배송 등 외부 결과를 수신하는 로직은 OrderOrchestrator에서 처리(혹은 같은 서비스 내에서 함께 처리)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
ckage com.example.sagasample.service; import com.example.sagasample.domain.Order; import com.example.sagasample.domain.OrderStatus; import com.example.sagasample.events.OrderCreatedEvent; import com.example.sagasample.repository.OrderRepository; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; @Service public class OrderService { private final OrderRepository orderRepository; private final KafkaTemplate<String, Object> kafkaTemplate;// JSON 직렬화/역직렬화private static final String ORDER_TOPIC = "order-events"; public OrderService(OrderRepository orderRepository, KafkaTemplate<String, Object> kafkaTemplate) { this.orderRepository = orderRepository; this.kafkaTemplate = kafkaTemplate; } @Transactional public Order createOrder(String productName, int quantity, int price) { // 1) Order 저장Order newOrder = new Order(productName, quantity, price); newOrder.setOrderStatus(OrderStatus.PAYMENT_PENDING); orderRepository.save(newOrder); // 2) Kafka로 이벤트 발행 (결제 서비스가 이 이벤트를 듣는다고 가정)OrderCreatedEvent event = new OrderCreatedEvent(newOrder.getId(), price * quantity); kafkaTemplate.send(ORDER_TOPIC, event); return newOrder; } @Transactional public void updateOrderStatus(Long orderId, OrderStatus status) { Order order = orderRepository.findById(orderId) .orElseThrow(() -> new RuntimeException("Order not found")); order.setOrderStatus(status); orderRepository.save(order); } }
참고: 실제로는 @Transactional 범위, 에러 발생 시 보상 트랜잭션, Outbox 패턴 등이 더 복잡하게 들어갈 수 있습니다.
5-2) OrderOrchestrator (오케스트레이션 로직)
Kafka Consumer로부터 PaymentCompletedEvent, PaymentFailedEvent, ShippingCompletedEvent 등을 수신하고, 이에 따라 Order 상태를 갱신하거나 보상 로직(결제 취소, 주문 취소 등)을 수행.
여기서는 배송 로직까지 함께 처리하거나, 필요시 “배송 서비스”로 이벤트를 발행할 수도 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58
package com.example.sagasample.service; import com.example.sagasample.domain.OrderStatus; import com.example.sagasample.events.PaymentCompletedEvent; import com.example.sagasample.events.PaymentFailedEvent; import com.example.sagasample.events.ShippingCompletedEvent; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; @Service public class OrderOrchestrator { private final OrderService orderService; private final KafkaPublisher kafkaPublisher;// 이벤트 발행(배송 요청 등) 담당 클래스 예시 public OrderOrchestrator(OrderService orderService, KafkaPublisher kafkaPublisher) { this.orderService = orderService; this.kafkaPublisher = kafkaPublisher; } /** * 결제 성공 이벤트 수신 */@KafkaListener(topics = "payment-events", groupId = "saga-example-group", containerFactory = "kafkaListenerContainerFactory") @Transactional public void handlePaymentCompleted(PaymentCompletedEvent event) { // 1) 주문 상태를 'PAID' 로 변경 orderService.updateOrderStatus(event.getOrderId(), OrderStatus.PAID); // 2) 배송 서비스로 배송 요청 이벤트 발행 (예: shipping-events) kafkaPublisher.sendShippingRequest(event.getOrderId()); } /** * 결제 실패 이벤트 수신 */@KafkaListener(topics = "payment-events", groupId = "saga-example-group", containerFactory = "kafkaListenerContainerFactory") @Transactional public void handlePaymentFailed(PaymentFailedEvent event) { // 1) 주문 상태를 'PAYMENT_FAILED' 로 변경 orderService.updateOrderStatus(event.getOrderId(), OrderStatus.PAYMENT_FAILED); // 2) 비즈니스 로직에 따라 주문 취소, 재시도 로직, 고객 알림 등 수행// 여기서는 간단히 주문을 취소한다고 가정 orderService.updateOrderStatus(event.getOrderId(), OrderStatus.CANCELLED); } /** * 배송 완료 이벤트 수신 */@KafkaListener(topics = "shipping-events", groupId = "saga-example-group", containerFactory = "kafkaListenerContainerFactory") @Transactional public void handleShippingCompleted(ShippingCompletedEvent event) { // 1) 주문 상태를 'COMPLETED' 로 업데이트 orderService.updateOrderStatus(event.getOrderId(), OrderStatus.COMPLETED); } }
위 코드는 하나의
@KafkaListener메서드에서 이벤트 타입별로 분기하는 대신, 메서드를 분리하여 처리했습니다.PaymentCompletedEvent,PaymentFailedEvent가 같은 토픽(payment-events)에서 오기 때문에 실제로는 컨테이너 설정이나 메시지 필드(T입 구분자) 등을 활용해 구분할 수 있습니다.
5-3) 간단한 KafkaPublisher 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package com.example.sagasample.service;
import com.example.sagasample.events.ShippingCompletedEvent;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
@Component
public class KafkaPublisher {
private final KafkaTemplate<String, Object> kafkaTemplate;
public KafkaPublisher(KafkaTemplate<String, Object> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendShippingRequest(Long orderId) {
// 실제로는 "배송 요청" 이벤트를 만들어 shipping-events 토픽으로 보냄// 예: ShippingRequestEvent 라는 별도 이벤트가 있을 수도 있음// 여기서는 "곧 배송 완료 이벤트가 날아온다고 치자" 정도로 간단화// 실제로는 배송 서비스가 ShippingRequestEvent 를 받고, 배송 후 ShippingCompletedEvent 를 발행
System.out.println(">>> Sending shipping request for orderId = " + orderId);
// shipping-request 이벤트 발행// kafkaTemplate.send("shipping-events", new ShippingRequestEvent(orderId));// (시뮬레이션) 바로 "배송 완료" 이벤트를 발행
kafkaTemplate.send("shipping-events", new ShippingCompletedEvent(orderId));
}
}
실제로는 배송 서비스가 별도로 존재하고, 해당 서비스가 ShippingRequestEvent를 받아서 배송 로직을 수행한 뒤 ShippingCompletedEvent를 발행해야 합니다. 여기서는 샘플로 간단히 “배송 요청 → 바로 배송 완료 이벤트 발행” 흐름을 시뮬레이션했습니다.
컨트롤러 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
package com.example.sagasample.controller;
import com.example.sagasample.domain.Order;
import com.example.sagasample.service.OrderService;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/orders")
public class OrderController {
private final OrderService orderService;
public OrderController(OrderService orderService) {
this.orderService = orderService;
}
@PostMapping
public Order createOrder(@RequestParam String productName,
@RequestParam int quantity,
@RequestParam int price) {
return orderService.createOrder(productName, quantity, price);
}
// 주문 조회, 상태 확인 등등...
}
결제 시뮬레이터 예시
실제로는 PaymentService가 별도의 마이크로서비스로 존재해야 합니다.
여기서는 이벤트를 흉내 내기 위해 간단히 “결제 시뮬레이터”를 만들어보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
package com.example.sagasample.service;
import com.example.sagasample.events.PaymentCompletedEvent;
import com.example.sagasample.events.PaymentFailedEvent;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import java.util.Random;
@Service
public class PaymentServiceSimulator {
private final KafkaTemplate<String, Object> kafkaTemplate;
private static final String PAYMENT_TOPIC = "payment-events";
private final Random random = new Random();
public PaymentServiceSimulator(KafkaTemplate<String, Object> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
// 실제로는 PaymentService가 order-events를 Subscribe 한 뒤// 결제를 시도하고, 성공/실패 이벤트를 발행해야 함.// 여기서는 간단히 API로 호출해서 시뮬레이션해볼 수 있도록 작성.public void simulatePayment(Long orderId) {
boolean success = random.nextBoolean();// 50% 확률로 결제 실패
if (success) {
PaymentCompletedEvent event = new PaymentCompletedEvent(orderId);
kafkaTemplate.send(PAYMENT_TOPIC, event);
System.out.println(">>> Payment success event fired: " + orderId);
} else {
PaymentFailedEvent event = new PaymentFailedEvent(orderId, "Card limit exceeded");
kafkaTemplate.send(PAYMENT_TOPIC, event);
System.out.println(">>> Payment failed event fired: " + orderId);
}
}
}
실무에서는 PaymentService가 @KafkaListener로 OrderCreatedEvent를 받고 결제를 수행한 뒤, PaymentCompletedEvent나 PaymentFailedEvent를 발행해야 합니다.
정리하자면
- 각 서비스가 분리되어 있다면,
OrderService는
order-events토픽에 이벤트 발행PaymentService는
order-events를 구독 → 결제 수행 →payment-events발행OrderOrchestrator(또는 동일한 OrderService 내의 Consumer)가
payment-events를 구독 → 다음 단계(배송 이벤트) 발행ShippingService는
shipping-events를 구독 → 배송 처리 →ShippingCompletedEvent발행다시 오케스트레이터가
ShippingCompletedEvent를 받고 최종 완료로 상태 변경
보상 트랜잭션(Compensation) 예시(주문 취소, 결제 취소, 재고 롤백 등)는 PaymentFailedEvent나 Shipping 실패 시점에서, 추가적으로 “재고 복원”이나 “결제 취소 API 호출” 등을 구현해야 합니다.
- Idempotency(멱등성), Outbox 패턴, DLQ(Dead Letter Queue) 처리, 재시도(Retry) 등은 실제 운영에 필수적으로 고려해야 할 요소입니다.
실무에서는:
각 서비스를 완전히 분리(별도 Git 리포지토리, 별도 DB, 별도 배포)
에러 및 보상 트랜잭션 로직을 더 정교화
테스트 & 모니터링(분산 트레이싱, 로그 수집 등) 체계를 구축
메시지 스키마(Avro/Protobuf/JSON)와 호환성(Backward/Forward Compatibility)
토픽 파티션과 컨슈머 그룹 설계
등을 추가로 고려하게 됩니다.
예시 코드가 자가 학습이나 PoC(Proof of Concept) 단계에서 SAGA 패턴을 간단히 시도해보는 데 도움이 되길 바랍니다.
QnA
1. RabbitMQ vs Kafka, 어떤 차이가 있고 Saga 패턴에는 어떻게 적용해야 할까?
Q
RabbitMQ와 Kafka를 비교했을 때 SAGA 패턴을 적용하는 방법이 어떻게 달라지나요? (강의에서는 RabbitMQ만 다루어서 Kafka 적용이 궁금합니다.)
두 메시지 브로커 중 어느 상황에서 어떤 것을 쓰는 것이 좋은지 알고 싶습니다.
A
- 아키텍처적인 차이
RabbitMQ: 전통적인 메시지 큐(Message Queue)로, 메시지가 들어오면 큐에서 소비자가 가져가는 방식. 라우팅 키, 익스체인지, 큐 등의 개념을 통해 메시지를 유연하게 전달할 수 있음. 전형적으로 ‘명령(Command)’ 스타일의 메시징에 적합.
Kafka: 분산 로그(Distributed Commit Log) 구조로, 메시지를 토픽에 기록하면 여러 컨슈머 그룹이 이를 구독. 스트리밍 처리, 대용량 데이터 처리, 이벤트 소싱 등에 강점.
- Saga 패턴 적용 시 고려점
- RabbitMQ 기반
메시지의 ‘순서’ 보장보다는 처리의 ‘일관성’에 무게를 두기 쉬움. 큐에 들어간 순서대로 소비하기는 하지만, 큐가 분산되는 구조가 아니라면 단일 지점(브로커) 장애에 대한 고려가 필요.
메시지 재처리(retry) 로직과 DLQ(Dead Letter Queue) 설정 등을 통해 보상 트랜잭션을 처리할 수 있음.
- Kafka 기반
파티셔닝(Partitioning)을 통해 대량의 메시지를 확장성 있게 처리 가능.
토픽에 기록된 메시지는 컨슈머가 offset을 관리하며 읽어가므로, 재처리나 장애 복구 시점을 세밀하게 제어할 수 있음(오프셋 롤백 등).
이벤트 소싱, CQRS, 스트리밍 분석 등의 아키텍처에 훨씬 적합.
- RabbitMQ 기반
- 결론
단순한 명령형 메시지 전달과 비교적 낮은 TPS(초당 트랜잭션 수)에서는 RabbitMQ가 쓰기 쉬울 수 있음.
이벤트 중심, 높은 처리량, 이벤트 소싱/CQRS 등을 고려한다면 Kafka가 더 적합한 경우가 많음.
SAGA 자체는 메시지 브로커에 크게 종속되지 않지만, 최종적 일관성을 보장하기 위한 재처리 메커니즘, 이벤트 중복 처리를 위한 Idempotency, 장애 복구 전략 등에 있어 Kafka가 주는 이점이 큼.
2. Orchestration Saga vs Choreography Saga, 언제 어떤 방식을 선택해야 할까?
Q
Orchestration 기반은 언제 써야 하고, Choreography 기반은 언제 써야 하나요?
두 방식 모두 장단점이 있을 텐데, 그 기준을 어떻게 잡아야 할까요?
A
- Choreography(코레오그래피)
이벤트 기반으로 각 서비스가 상호 간 이벤트를 발행하고 구독하여 다음 단계를 진행.
작은 규모 혹은 이벤트 흐름이 단순할 때 유리.
서비스 간 의존성이 커지고 이벤트 흐름이 복잡해지면 “이벤트 폭발(Event Explosion)”이 발생할 수 있음.
‘별도의 중앙 집중 오케스트레이터’ 없이 자체적으로 이벤트를 주고받는 구조.
- Orchestration(오케스트레이션)
중앙에서 프로세스 흐름을 제어하는 “오케스트레이터(Orchestrator)”가 존재.
각 서비스는 오케스트레이터가 지시한 순서대로 작업을 수행하고 이벤트(또는 콜백)로 결과를 보고.
로직이 복잡해질수록 오케스트레이터의 역할이 매우 중요해지고, 해당 서비스가 단일 실패점(Single Point of Failure)이 될 가능성도 있음.
이벤트 흐름이 복잡하거나 단계가 많은 경우 로직 관리가 상대적으로 쉬울 수 있음(중앙에서 흐름 관리를 하므로).
- 선택 기준
서비스 간 결합도: 단순히 2~3개의 서비스가 연결될 때는 Choreography가 가볍고 빠를 수 있음. 그러나 5개 이상의 도메인이 얽히고 단계가 많아지면 Orchestration이 유지보수에 유리.
업무 흐름 복잡도: 여러 단계가 순차/병렬적으로 섞여 있고, 에러 핸들링 로직이 다양하다면 Orchestration으로 중앙 집중 제어.
개발/운영 편의성: Choreography는 이벤트를 잘 이해해야 하고, Orchestration은 중앙 집중 로직을 잘 설계해야 한다는 차이가 있음. 팀 내 역량과 아키텍처 방향에 따라 선택.
3. 보상 트랜잭션(Compensation)과 실패 시 재처리는 어떻게 해야 할까?
Q
보상 트랜잭션이 실패했을 때는 어떻게 처리해야 하나요?
DLQ나 재시도 로직을 어떻게 설계해야 하며, 보상 트랜잭션이 연쇄적으로 실패할 수 있는데 이에 대한 대응 방안은 무엇인지 궁금합니다.
이미 커밋(Commit) 후에 메시지를 발행했는데, 롤백 상황이 되면 발행된 메시지를 어떻게 처리해야 하나요?
A
- 보상 트랜잭션(Compensation)의 개념
정방향 트랜잭션이 성공한 후, 오류가 발생하면 이를 되돌리기 위해 ‘반대 작업’을 수행하는 것.
예:
주문 생성 → 결제 성공상황에서 배송 실패 시, ‘결제 취소’가 보상 트랜잭션이 될 수 있음.
- 보상 트랜잭션 실패 시 재처리
재시도(Retry) 정책: 일정 횟수까지는 재시도. 재시도 횟수를 초과하면 DLQ나 관리자 개입이 필요.
DLQ(Dead Letter Queue) 또는 보상 전용 토픽: 보상 트랜잭션용 메시지가 계속 실패할 경우, 이후 수동 확인을 위해 저장할 별도 큐/토픽을 운영.
Outbox 패턴: 로컬 트랜잭션과 이벤트 발행을 원자적으로 처리하기 위한 패턴. 이벤트를 DB 테이블(Outbox)에 먼저 저장하고, 별도 프로세스가 테이블에 있는 이벤트를 메시지 브로커에 전달하여 발행-커밋 간 불일치를 방지.
- 이미 발행된 메시지에 대한 롤백 처리
Idempotency(멱등성) 보장: 메시지 소비 측에서 동일한 메시지가 여러 번 와도 로직을 2번 이상 수행하지 않도록 설계.
‘보상’ 메시지 발행: 단순히 이전 메시지를 취소하는 대신, 상태를 원복하는 새로운 이벤트를 발행해 소비 측에서 취소 혹은 보정 로직을 수행하게 함.
트랜잭션 경계 재설계: 중요한 비즈니스 로직이라면, 메시지를 발행하는 시점을 로컬 트랜잭션(commit)과 철저히 동기화. 또는 Outbox 패턴을 고려.
4. 메시지 중복, 메시지 순서 보장 문제는 어떻게 해결하나요?
Q
메시지를 중복으로 받거나, 순서가 뒤엉키는 문제를 어떻게 해결해야 할까요?
특히 Kafka 환경에서 파티셔닝이 많아지면 순서 보장이 어려워지는데, 이를 어떻게 처리하나요?
A
- 중복 문제(Idempotency)
- 소비자 측에서 중복 메시지에 대응하기 위한 방법:
비즈니스 키(주문번호, 결제번호 등)를 기반으로 이미 처리된 이벤트인지 체크.
Deduplication Store: Redis나 DB에 처리된 이벤트 ID를 저장하여 중복이면 무시.
- Kafka에서는 offset commit을 통해 같은 메시지를 중복으로 가져가지 않지만, 장애 복구 시 다시 읽을 수 있기 때문에 멱등성 처리가 필요.
- 소비자 측에서 중복 메시지에 대응하기 위한 방법:
- 순서 문제(Ordering)
Kafka는 같은 파티션 내에서는 메시지 순서를 보장하지만, 파티션을 나누면 글로벌 순서는 보장되지 않음.
글로벌 순서가 정말 필요한 경우 파티션을 1개만 쓰거나, 특정 키 기반으로 파티션을 묶어서 해당 키에 대해서만 순서를 보장.
순서를 절대적으로 맞추기 어렵다면, 최종 일관성 관점에서 이벤트 설계를 다시 고려해야 함(‘이벤트중심’ + ‘상태머신’).
5. Kafka 파티션, 토픽 개념이 어렵습니다. 어떻게 이해하고 설정해야 할까요?
Q
- Kafka 토픽과 파티션 개념이 너무 어렵습니다. 어떤 기준으로 파티션 개수를 정해야 할까요?
A
토픽(Topic): 메시지의 카테고리 혹은 채널.
파티션(Partition): 토픽을 물리적으로 분할한 단위. 병렬 처리와 확장성에 큰 역할.
- 파티션 개수 설정 기준
소비자 수: 컨슈머 그룹 내 최대 병렬 소비가 가능하도록 파티션 수를 적절히 잡아야 함(파티션 개수 ≥ 컨슈머 스레드 수).
예상 트래픽: 초당 처리해야 할 메시지 수가 많을수록 파티션을 늘려 확장성(Throughput)을 높임.
메시지 순서: 파티션을 늘리면 순서 보장은 파티션 단위로만 가능함.
- 실무 팁
처음부터 파티션을 너무 작게 잡기보다는 조금 넉넉하게 잡고, 운영 중에 토픽 리더밸런싱(Re-partitioning) 계획을 세워두는 것이 좋음.
메시지 키를 어떻게 설정할지(Partition Key)에 따라 파티션 분배가 달라지고, 이는 데이터의 균등 분산과 순서 보장 전략에 영향을 미침.
6. Choreography 방식으로 복잡한 구조를 구현할 때, 서비스 간 의존성이 커지는 문제와 장애 시 보상 트랜잭션은 어떻게 처리하나요?
Q
Choreography는 이벤트가 너무 많이 오가서 복잡해지는데, 이를 어떻게 관리하나요?
장애 시 보상 트랜잭션 처리도 이벤트 기반으로만 가능할지 궁금합니다.
A
- Choreography에서 발생하는 문제점
이벤트 폭발: 여러 서비스가 서로 이벤트를 발행/구독하다 보면, 비즈니스 로직 흐름이 보이지 않거나 순서 파악이 힘들어질 수 있음.
서비스별 이벤트 핸들러가 많아지면, 한 곳에서 흐름을 파악하기 어렵고 디버깅이 힘들어짐.
- 관리 전략
도메인 이벤트 설계: 각 도메인에서 발행하는 이벤트의 명확한 정의와 표준화. “어떤 상황에서 어떤 이벤트를 발행하는가?”를 엄격히 정함.
이벤트 트레이싱(Logging/Tracing): 중앙화된 로깅/트레이싱 시스템(예: ELK, Zipkin 등)으로 이벤트의 흐름을 추적.
보상 트랜잭션: 이벤트 기반으로 다시 역이벤트를 발행하거나, 별도 보상 프로세스가 이벤트를 수신해 상태를 복원.
- 언제 Orchestration으로 전환할지
서비스/도메인 개수가 늘고, 이벤트 흐름의 분기가 복잡해진다면 Orchestration을 고려해볼 시점.
Choreography는 소규모, 단순 흐름, 빠른 확장에 용이하지만 복잡도가 커지면 관리가 어려움.
7. Update(수정) 시 보상 트랜잭션은 어떻게 관리해야 할까?
Q
- 생성/삭제(Create/Delete)의 경우 롤백이 비교적 간단하지만, Update(수정)는 이전 상태를 저장하고 있어야 롤백할 수 있습니다. 이전 데이터를 어디에 저장해야 할까요?
A
- 이전 상태(Pre-State) 저장 전략
이벤트 소싱(Event Sourcing): 이벤트를 쌓아두고, 필요 시 특정 시점으로 되돌아갈 수 있음.
스냅샷(Snapshot) + 이벤트: 데이터가 복잡해질수록 특정 시점의 스냅샷을 떠놓고, 이후 이벤트를 재생하여 상태 복원.
히스토리 테이블: RDB를 쓰는 경우, Update 시 이전 데이터를 별도 기록 테이블에 저장해두었다가 롤백 시 참조.
- 주의사항
업데이트가 빈번한 데이터라면 기록 용량이 급격히 늘어날 수 있으므로 보상 트랜잭션이 꼭 필요한 필수 필드만 버전 정보를 저장하는 방식을 택하기도 함.
너무 세밀하게 이전 상태를 모두 저장하면 시스템 복잡도가 증가하므로, 서비스 도메인 특성에 따라 절충점을 찾는 것이 중요.
8. SAGA 롤백 순서를 임의로 바꿨을 때 데이터 정합성 문제는 없을까?
Q
예: 주문(요청) → 재고(동기) → 결제(비동기) → 배송(비동기) 순서로 처리했지만, 배송 실패 시 롤백 순서를 재고 복원(동기) → 주문 상태 변경 → 결제 취소(비동기)로 했다.
이렇게 서비스마다 롤백 순서를 다르게 두었을 때 문제가 없을지 궁금합니다. SAGA에서 롤백 우선순위를 어떻게 결정해야 할까요?
A
정방향 트랜잭션에서의 순서와 보상 트랜잭션에서의 순서가 반드시 역순일 필요는 없으나, 데이터 무결성과 비즈니스 요구사항을 고려해야 함.
- 핵심 고려사항
비즈니스 중요도: “재고”가 먼저 복원되어야 한다는 요구사항이 비즈니스적으로 타당하면, 재고 복원부터 하는 것이 맞음.
데이터 정합성: 특정 서비스가 롤백되기 전에 다른 서비스를 롤백해버리면, 중간 상태에서 다른 에러가 발생하거나 논리적 충돌이 생길 수 있음(결제를 취소했는데 재고가 아직 복원 안 되어 다른 주문에 영향을 줄 수도 있음).
오케스트레이터 또는 개별 서비스에서 이 순서를 제어할 때, 장애 발생 시 재시도 로직을 철저히 설계.
- 정리
- 보상 트랜잭션 순서는 반드시 ‘정방향의 역순’이어야 하는 것은 아니지만, ‘비즈니스 로직 상 안전하게 되돌릴 수 있는 순서’를 고려해야 한다. 중간 상태에서 오류가 나면 다시 재시도하거나, 별도의 모니터링 및 에러 처리가 필요.
9. CQRS와 Saga를 함께 적용하면 너무 복잡해집니다. 실무에서는 어느 정도로 관리하나요?
Q
CQRS(읽기/쓰기 분리) + Saga(분산 트랜잭션) + 이벤트 소싱까지 도입하려다 보니 너무 복잡해졌습니다. 실무에서는 어느 범위까지 적용하나요?
CRUD 같은 간단한 기능도 이렇게 복잡하게 만들어야 하는지 고민됩니다.
A
- 실무 적용 수준
모든 서비스를 이벤트 소싱 + CQRS로 구현하는 것은 부담이 큼.
비즈니스 임팩트가 큰 핵심 도메인(주문, 결제, 재고 등)에만 CQRS & Saga를 적용하고, 나머지는 상대적으로 단순한 CRUD로 구성하는 혼합 전략을 사용하는 경우가 많음.
‘적절한 수준’의 도입이 중요. 지나친 아키텍처 도입으로 생산성이 떨어지면 유지보수 비용이 더 커짐.
- 점진적 도입 방법
먼저 도메인 분리와 DB 분리: MSA의 기본 전제인 개별 서비스의 독립성을 어느 정도 확보.
이벤트 발행(혹은 REST API)으로 서비스 간 의존성을 느슨하게 유지: 꼭 필요한 곳부터 Saga를 적용.
CQRS는 필요성에 따라 부분 적용: 조회 부하가 많은 서비스나, 이벤트 소싱이 필요한 경우만 먼저 도입.
모니터링/테스트 전략을 마련: 분산 트랜잭션인 만큼 장애 시 재처리 로직을 미리 마련해야 함.
10. SAGA 패턴 테스트는 어떻게 해야 할까?
Q
- 분산 트랜잭션을 테스트하려면 서비스 간 통합 테스트가 필요해 보이는데, 어떤 방식을 쓰나요?
A
- 통합 테스트(Integration Test)
도커(Docker) 등으로 각 서비스와 메시지 브로커(Kafka/RabbitMQ 등)를 띄운 뒤 시나리오 테스트 진행.
정상 처리 시나리오, 부분 실패 시나리오(결제 실패, 배송 실패 등), 보상 트랜잭션 실패 시나리오 등을 모두 넣어야 함.
- 계측 및 모니터링
분산 트랜잭션은 여러 서비스/큐가 얽히므로, Zipkin, Jaeger 등의 분산 트레이싱 툴로 트랜잭션 경로를 시각화.
에러 발생 시 메시지가 어떻게 재시도/보상되고 있는지 이벤트 로그를 확인.
- 계속적 통합(CI) & 계속적 배포(CD)
- 변경 사항이 생길 때마다 자동화된 통합 테스트를 돌려 SAGA 시나리오가 깨지지 않는지 확인.
11. 실제 서비스(현업)에서 SAGA 패턴을 적용할 때 겪은 문제와 해결책이 궁금합니다.
Q
실무에서 발생한 장애 사례나 오류, 그 해결 방안을 듣고 싶습니다.
실무에선 코드 레벨에서 어떻게 구현하고, 모니터링/로깅은 어떻게 하는지 궁금합니다.
A
- 주요 장애 사례
메시지 중복 처리 실패: 멱등성 처리가 제대로 안 되어 중복 결제/중복 주문이 발생. → 트랜잭션 아이디 기반 중복 체크 및 DB Lock/Unique 제약 등으로 해결.
보상 트랜잭션 무한 실패: 결제 취소 API가 여러 차례 실패해 DLQ로 쌓였는데, 운영에서 이를 놓치는 경우. → DLQ 모니터링 시스템이나 주기적 알람으로 대응.
Orchestrator 장애: 중앙 오케스트레이터 서비스 다운으로 전체 트랜잭션의 흐름이 중단. → 고가용성(HA) 구성 + 장애 시 이벤트 재처리 설계.
- 해결 방안 및 운영 전략
모니터링/알람: 각 단계별 이벤트 성공/실패 카운트를 모니터링하고, 일정 임계치를 넘으면 Slack, 문자 등으로 실시간 알람.
Idempotent Consumer: 동일 이벤트 중복 처리 방지. 결제/재고/포인트처럼 금전적 트랜잭션이 관여되는 도메인에는 반드시 적용.
재처리(Replay) 로직: 보상 트랜잭션 또는 특정 이벤트를 다시 재생할 수 있도록 Kafka 오프셋이나 DB Outbox를 이용.
장애 대응 문서화: 분산 환경에서는 장애가 여러 양상으로 발생하므로, 장애 시나리오를 문서화하고 사전에 대비.
12. MSA에서 분산 트랜잭션이 많아지면 장애 대응, 고가용성, 확장성, 데이터 일관성 등 생각할 게 많습니다. 어떤 접근이 좋을까요?
Q
- MSA로 전환하면 고려해야 할 키워드들이 많아졌는데, 각각을 어떻게 우선순위로 두고 대응하면 좋을까요?
A
- 도메인 우선 설계
비즈니스 로직이 가장 중요한 도메인부터 분산 트랜잭션 설계를 철저히.
트랜잭션이 많이 발생하지 않는 도메인은 단순 API 콜만으로 처리하고, 핵심 도메인만 이벤트 기반/사가 패턴 적용.
- 관심사의 분리
“확장성, 장애 대응, 데이터 일관성”은 각각 인프라 및 아키텍처 차원의 문제와 서비스 내부 로직 문제로 구분해 접근.
예: Kafka나 RabbitMQ 클러스터 구성, 모니터링, 알람, 로그 수집은 DevOps/인프라 측면에서 먼저 안정화.
- 점진적 개선
한 번에 모든 것을 잘하려고 하면 복잡도가 폭발.
트랜잭션 경계, 이벤트 발행-소비, 보상 트랜잭션 로직부터 단계적으로 도입하고, 점차 CQRS나 이벤트 소싱을 더해 나감.
13. Saga 패턴을 적용할 때 꼭 고려해야 할 핵심 포인트는?
Q
- 사가 패턴을 실무에 적용한다면, 놓치기 쉬운 부분이나 핵심 고려사항은 무엇인가요?
A
- 데이터 멱등성(Idempotency)과 중복 처리
- 분산 환경에서 이벤트가 중복으로 발생하거나 순서가 어긋날 수 있으므로, 소비 단에서 안전장치가 필요.
- 보상 트랜잭션의 설계
- 실패 시 어떤 방식으로, 어느 단계부터, 어떤 순서로 롤백할지 사전에 명확히 정의.
- 오케스트레이션 vs 코레오그래피 선택
- 도메인 규모, 이벤트 복잡도, 팀 역량에 따라 어떤 방식을 택할지 결정.
- 장애 및 예외 상황 모니터링
- DLQ, 재시도 로직, Outbox 패턴 등 장애가 발생했을 때 어떻게 감지하고 회복할지 구체적으로 준비.
- 테스트 및 운영 전략
- 통합 테스트, 분산 트레이싱, 로깅/모니터링 환경을 잘 구축해야 실제 장애 시 빠른 원인 파악이 가능.
14. 보상 트랜잭션조차 실패할 수 있을 때, Outbox 패턴 말고 추가 대안은 없을까?
Q
단순히 메시지를 ‘보상’ 방향으로 되돌리는 것뿐 아니라, 보상 트랜잭션 자체가 또 실패할 가능성도 고려해야 합니다.
일단 DLQ(Dead Letter Queue)와 재시도 로직을 떠올렸고, Outbox 패턴 정도는 알고 있는데, 그 외에 추가적으로 쓸 만한 패턴이나 해결 방안이 있을까요?
A
Outbox 패턴은 이벤트 발행과 로컬 트랜잭션을 원자적으로 묶어 메시지 유실을 줄이는 데 매우 유용한 패턴입니다. 그러나 보상 트랜잭션 자체가 반복 실패할 경우에는 그보다 한 단계 더 상위의 오케스트레이션·모니터링·재처리 전략이 필요합니다. (아래 예시참고)
1) Orchestrator + 상태 기계(State Machine) 관리
Orchestration Saga를 좀 더 강화하여, 중앙 오케스트레이터(또는 Saga Manager)가 각 단계별 상태를 추적하고, 실패 시 보상 트랜잭션의 상태도 별도로 관리.
- 상태 기계(혹은 Workflow) 개념을 사용해, 현재 트랜잭션이 어느 단계에서 얼마나 재시도했고, 어떤 이유로 실패했는지를 기록.
- 예) Camunda, Zeebe, Netflix Conductor, Temporal.io 등 외부 워크플로우/오케스트레이션 엔진을 도입하여 보상 실패까지 상세하게 관리할 수 있음.
보상 트랜잭션이 계속 실패할 경우, 최종적으로 인간(운영자) 개입이 필요한 상태로 전환시키고, 모니터링 알람을 울리게 할 수도 있음.
2) TCC (Try-Confirm/Cancel) 패턴
- TCC는 Saga 패턴과 유사한 분산 트랜잭션 보장 기법 중 하나로,
Try: 자원을 사전에 예약(임시로 홀딩)
Confirm: 실제 커밋
Cancel: 보상/취소
- 로직으로 구성됩니다.
각 단계에서 자원을 예약(Try)하는 순간 실제 자원이 고정(홀딩)되므로, 이후 Cancel 단계에서 취소할 때 어느 정도 멱등성이 보장됨.
- 결제/재고 등의 자원이 확실히 “홀딩” 가능한 구조라면 TCC를 쓰는 게 보상 트랜잭션 실패 시 발생하는 재시도 문제를 줄이는 데 도움이 됩니다.
- 예를 들어, 결제 프로세스에서도 결제액을 완전히 빼놓지는 않고, 일정 시간(세션) 동안 “승인 보류” 상태로 두었다가 확정 시점에 Confirm, 취소 시점에 Cancel을 수행.
3) 재시도(Retry) + DLQ + 모니터링
이미 Outbox 패턴으로 메시지 유실 문제를 줄였다고 해도, 그 메시지를 소비하는 쪽(보상 트랜잭션 실행)에서 실패할 가능성이 존재함.
재시도 정책(지수 백오프, 최대 재시도 횟수 등) + DLQ(Dead Letter Queue)를 반드시 세팅해둬야 함.
단건 재시도: 최대 n번까지 재시도.
DLQ 이동: n번 실패 후 DLQ로 이동.
모니터링/알람: DLQ에 쌓인 메시지가 늘어나면, 슬랙·이메일·SMS 등으로 알람.
수동 개입: 운영자가 메시지를 확인하고, 재프로세싱할지(Replay) 또는 완전히 중단할지(Manual Cancel) 결정.
TipOutbox 테이블(혹은 이벤트 테이블)에 “처리 상태” 필드를 추가하여, 보상 트랜잭션 성공/실패/재시도 횟수 등을 기록하는 방안도 많이 쓰입니다.DB 내에서 상태를 추적하면, 운영자가 웹 대시보드나 SQL 쿼리로 직접 확인하고 재처리를 시도할 수 있는 장점이 있습니다.
1
<hr>
4) 이벤트 소싱(Event Sourcing) + CQRS
이벤트 소싱을 통해 모든 상태 변화를 이벤트로 기록해두면, 보상 트랜잭션 실패로 인해 데이터 정합성 문제가 생겼을 때, 특정 시점으로 되돌아가 재처리를 시도하거나(Replay), 문제 부분을 재구성할 수 있음.
CQRS와 함께 적용하는 경우, 쓰기(커맨드)와 읽기(조회) 모델을 분리해 두어, 보상 트랜잭션을 재실행하더라도 조회 모델은 최종 일관성만 맞으면 되는 방식으로 설계할 수 있음.
다만 이벤트 소싱은 운영과 유지보수 복잡도가 크게 증가하므로, 실제 프로젝트에서 꼭 필요한 핵심 도메인에 한해 점진적으로 도입하는 전략이 권장됨.
5) 재처리를 위한 특별 EndPoint 혹은 관리자 도구
- 이미 발행된 이벤트나 보상 실패 이벤트를 다시 처리(Replay)하고 싶은 상황이 생길 수 있음.
- 예) “배송 취소” 트랜잭션이 네트워크 장애로 계속 실패 -> DLQ에 쌓임 -> 장애 해소 후에 이 메시지를 다시 처리해야 함.
- 이럴 때,
수동으로 DLQ 메시지를 다시 정상 큐(or 토픽)로 옮기거나,
특별한 API(관리자용)나 콘솔을 통해 “재처리”를 트리거하는 방식을 쓸 수 있음.
- 보상 트랜잭션 자체가 여전히 실패한다면, 궁극적으로 인적 개입을 통해 DB 수정을 하거나, 비즈니스 정책에 맞춰 “이 주문은 완전히 취소 후 재주문하세요” 같은 시나리오를 안내할 수도 있음.
참고 자료
https://devocean.sk.com/blog/techBoardDetail.do?ID=165445&boardType=techBlog&ref=codenary
https://www.youtube.com/watch?v=amTJyIE1wO0&feature=youtu.be
댓글
궁금한 점, 피드백, 오류 제보를 남겨 주세요.