[TIL] Redis Practical Master Class Lecture 1 - Core Architecture and Caching Strategies
Redis in-memory structure and single-threaded architecture, caching strategies, distributed locks, and concurrency problem resolution
한국어 원문은 여기에서 볼 수 있습니다.
What I Learned
Redis core architecture and fundamentals
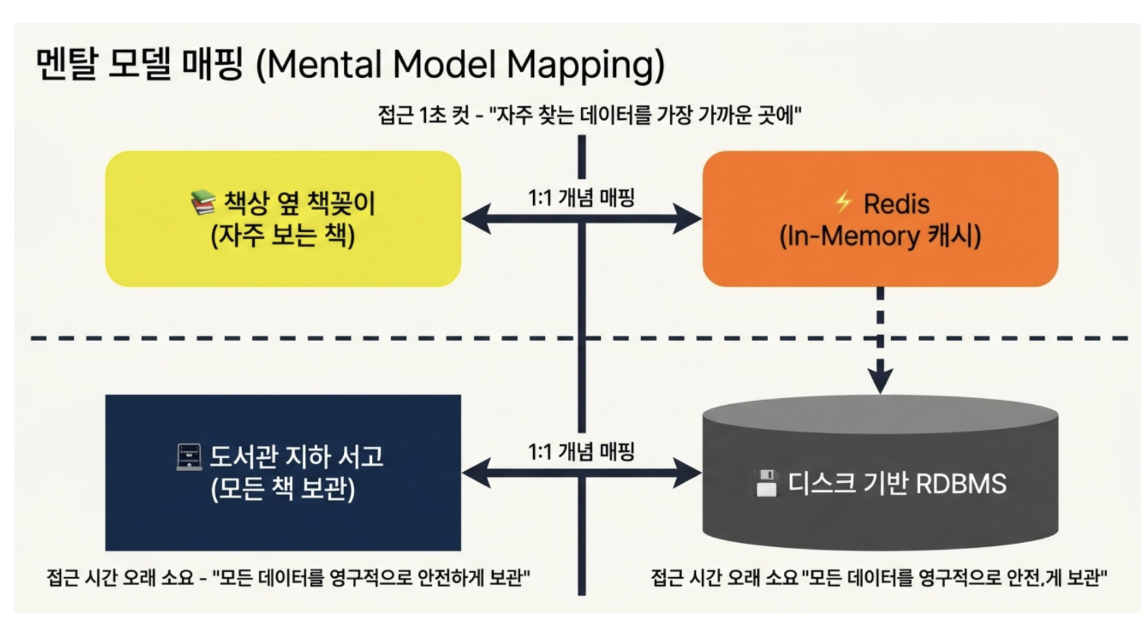
If the existing disk-based DB was like walking down to the library library in the basement to find a heavy book and take it out,
Redis is like placing a frequently read book on a small bookshelf next to your desk and taking it out in just one second.
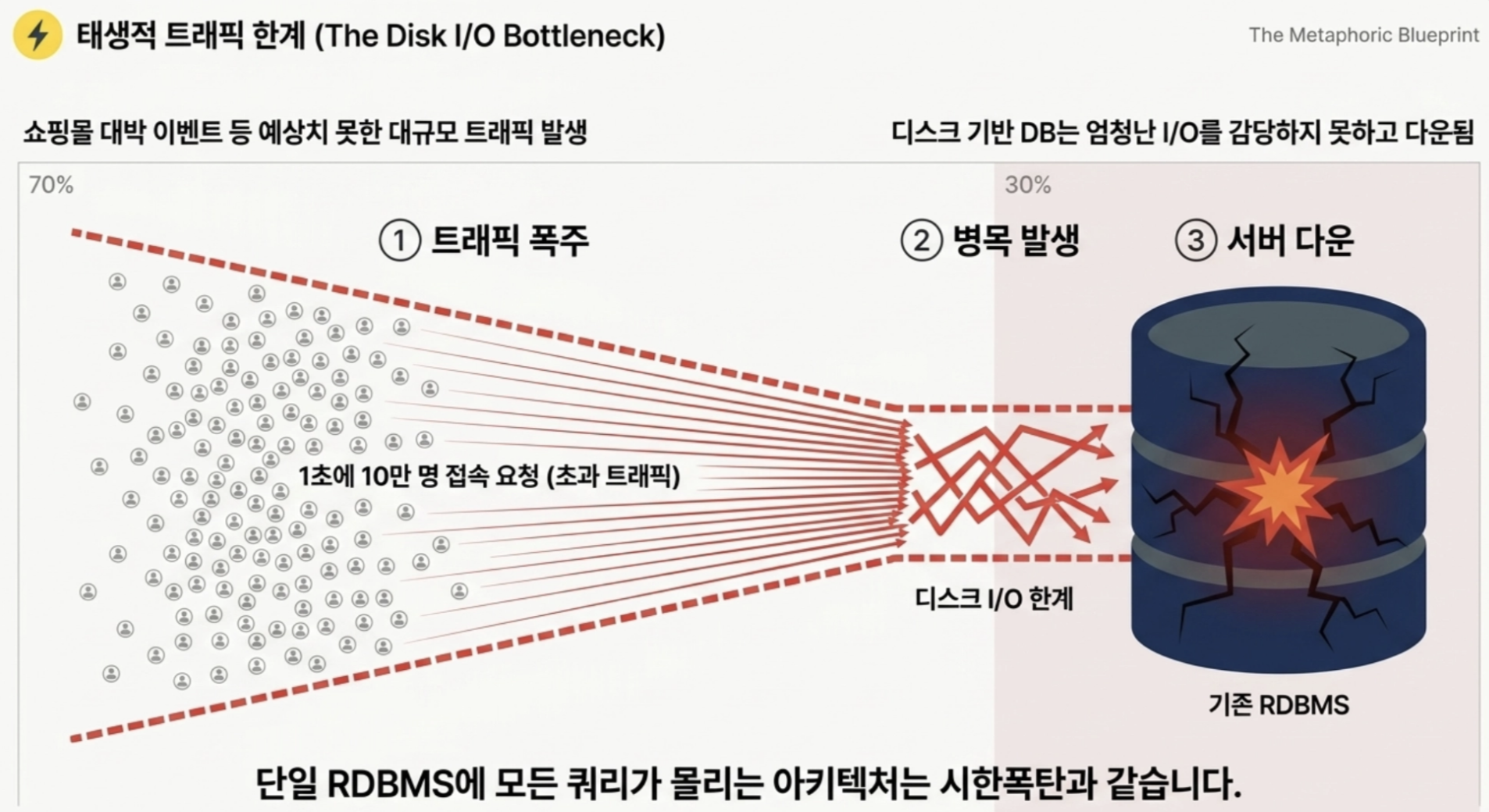
Q If the shopping mall becomes a hit and 100,000 customers access the main page per second, what will happen to the server if only the existing DBMS is used?
The server crashed due to too many queries in the DB.
Disk-based DBMS is inherently difficult to handle enormous traffic (I/O).
→ To prevent servers from crashing and provide smooth services, Redis, a fast and stable cache system, has become essential in the backend architecture.
1
What is Redis & Comparison of Competing Technologies
- Redis
- Abbreviation for REmote Dictionary Server
- REmote (remote): means that it exists as a remote (external) process, not inside our application program.
- Dictionary: A data structure consisting of a pair of Key and Value, like Python’s dictionary or Java’s HashMap.
- Why is In-Memory so overwhelmingly faster than disk? (physical differences)
- RAM (memory) reads and writes data purely through the movement of electrons through logic circuits.
- Due to this physical difference, memory access speeds are at least 400 to 1,000 times faster than disk.
- Before you even blink your eyes, Redis is already physically capable of inserting and removing data hundreds of thousands of times.
- RAM (memory) reads and writes data purely through the movement of electrons through logic circuits.
- Why Redis trumps Memcached
- When a shopping mall creates a ‘real-time purchasing ranking board’,
- When using Memcached, all ranking data (strings) must be imported from DB or Memcached into application memory, sorted at the application level, and then pushed back into Memcached.
- If another user updates the score during this process, data consistency is broken (Race Condition)- When using Redis, you only need to issue a single
ZADDcommand using the internal Sorted Set (ZSET) data structure, and Redis will perfectly sort tens of thousands of items per second in memory. - A completely different level in terms of development difficulty and performance
- If another user updates the score during this process, data consistency is broken (Race Condition)- When using Redis, you only need to issue a single
- When using Memcached, all ranking data (strings) must be imported from DB or Memcached into application memory, sorted at the application level, and then pushed back into Memcached.
- When a shopping mall creates a ‘real-time purchasing ranking board’,
Comparison table of competitive secrets
Compare items Redis Memcached RDBMS (for cache) Local cache (Ehcache, etc.) speed Very fast (In-Memory) Very fast (In-Memory) Slow (Disk I/O) Fastest (no network I/O) Data structure support Rich collection of more than 5 types Only String (Key-Value) Tables, views, etc. Object self storage Data Persistence Support (RDB snapshot, AOF) Not supported (will evaporate when the server is turned off) Full support (ACID) Not supported (will evaporate when the server is turned off) Support for distributed environments Clustering, replication, Sentinel Third party dependency Replication support (heavy) Not supported Typical usage scenario Ranking, Queue, Session, Global Cache Simple text/session caching Data that requires permanent retention Settings, static data from a single server
Deepening single-threaded architecture
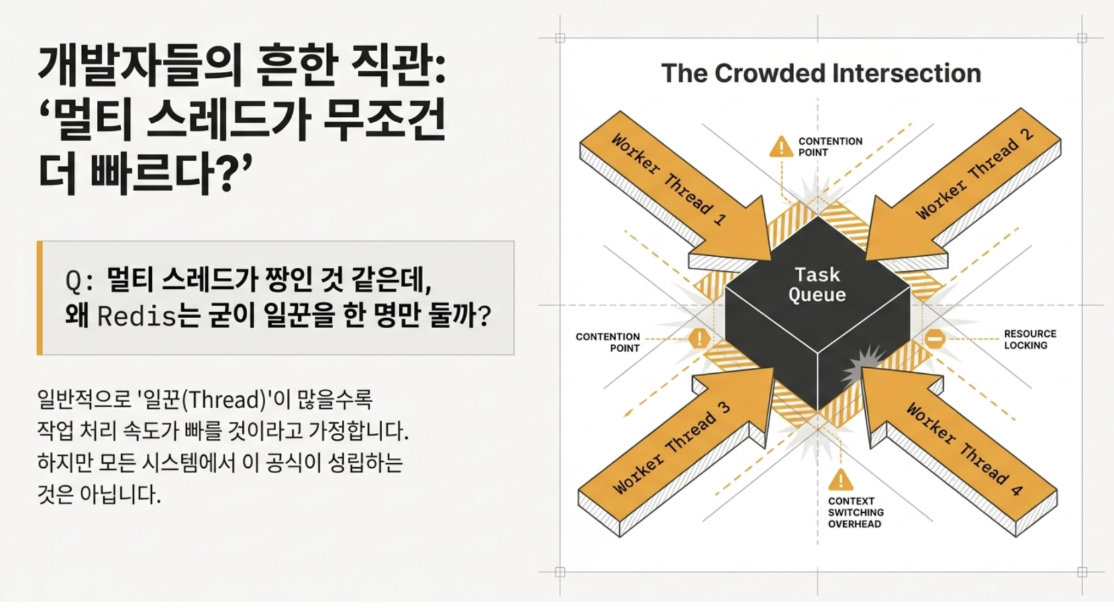
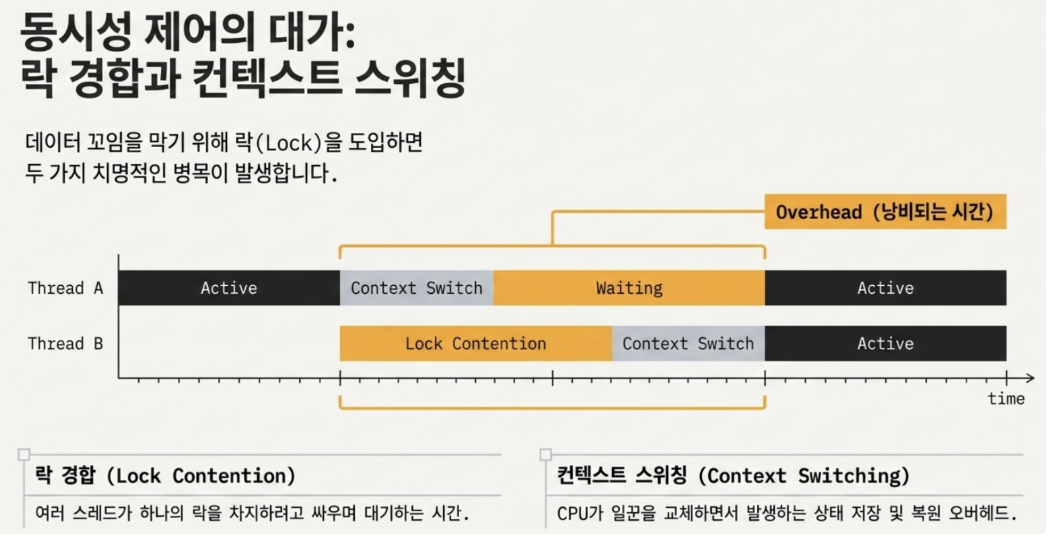
Q Multi-threading seems to be the best, but why did Redis choose to have only one worker
- If multiple threads access data at the same time, the data may become entangled, so this is done to prevent that.
→ Multi-threading causes context switching overhead and lock contention problems as multiple threads fight to take over the lock. ⇒ Since Redis’ memory operation itself is so fast, we decided that it would be better to process it like crazy alone rather than locking it and waiting.
- Understanding event loop-based multiplexing
- If compared to a waiter at a restaurant
- Equipped with multiplexing, Redis does not wait for the customer to select a menu, but moves at lightning speed only when an event occurs.
- If compared to a waiter at a restaurant
- Traffic situation time sequence processing flow comparison
Assuming that three write requests (A, B, C) come in at the same time,
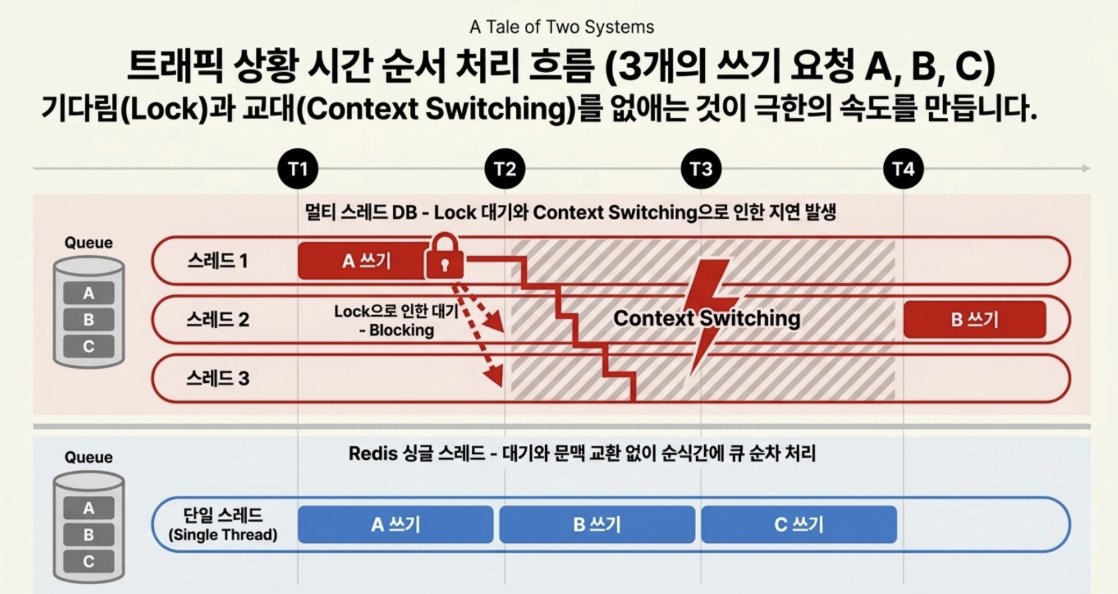
- Redis single thread → Processing is completed instantly, ensuring atomicity, without waiting for locks or exchanging context!
Caching Strategy Scenario
According to the Pareto Principle, 80% of all requests come from 20% of the data.
 We will see a strategy for caching this 20%
We will see a strategy for caching this 20%
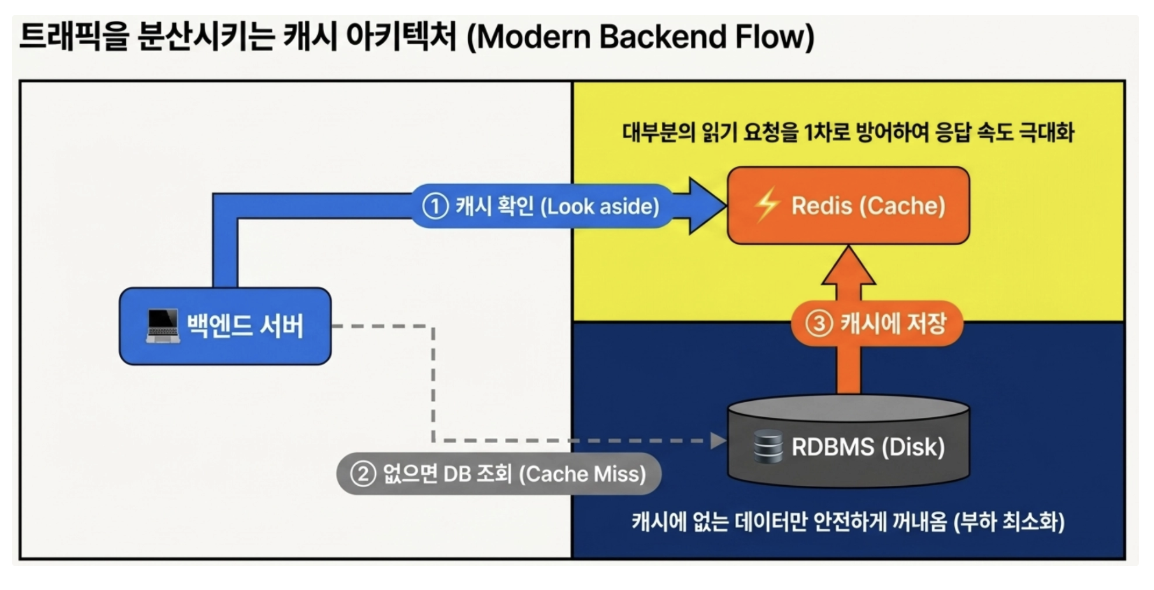
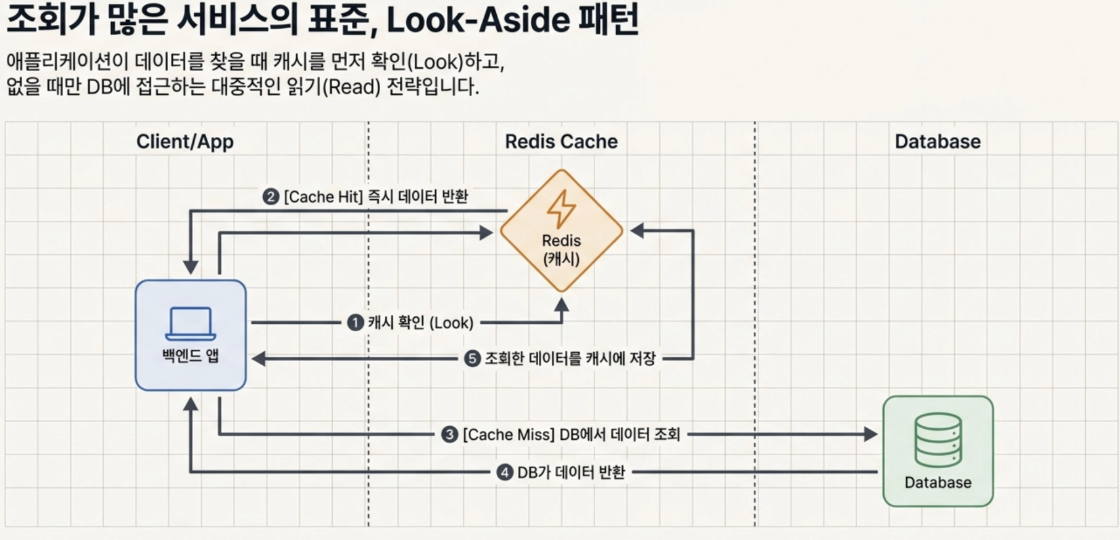
- Look-Aside (Cache-Aside) Pattern
The most popular strategy is to first look at the cache when the application is looking for data, and if not, retrieve it from the DB and push it into the cache.
Suitable for services with many reads
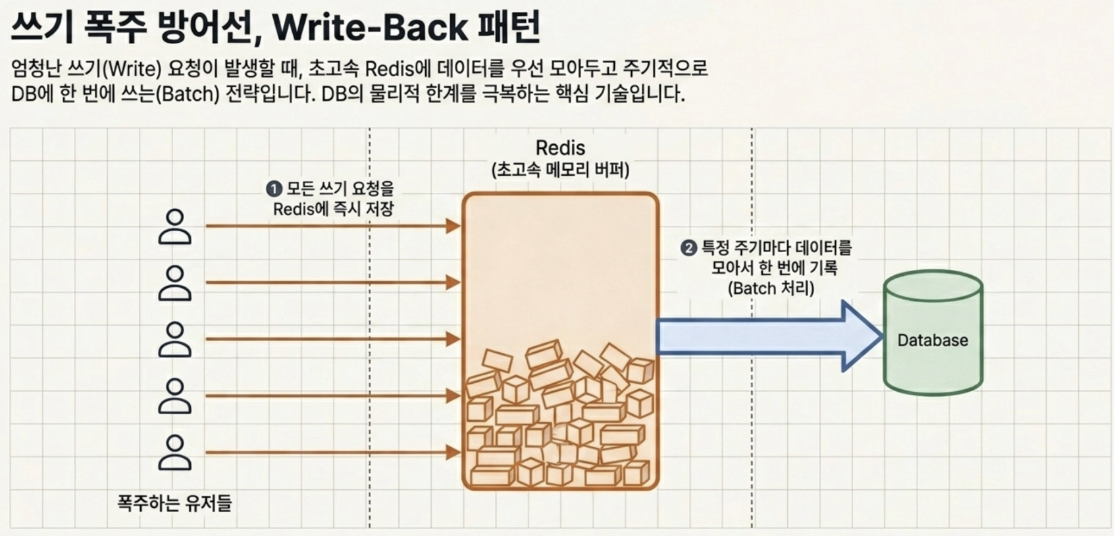
- Write-Back Pattern
A strategy of first putting all data into Redis, which is extremely fast, then collecting it periodically and writing it to the DB at once (batch)
Prevents the DB from exploding in the event of a huge write request, such as a flood of ‘likes’ on YouTube live broadcasts.
When and how is cache invalidation performed?
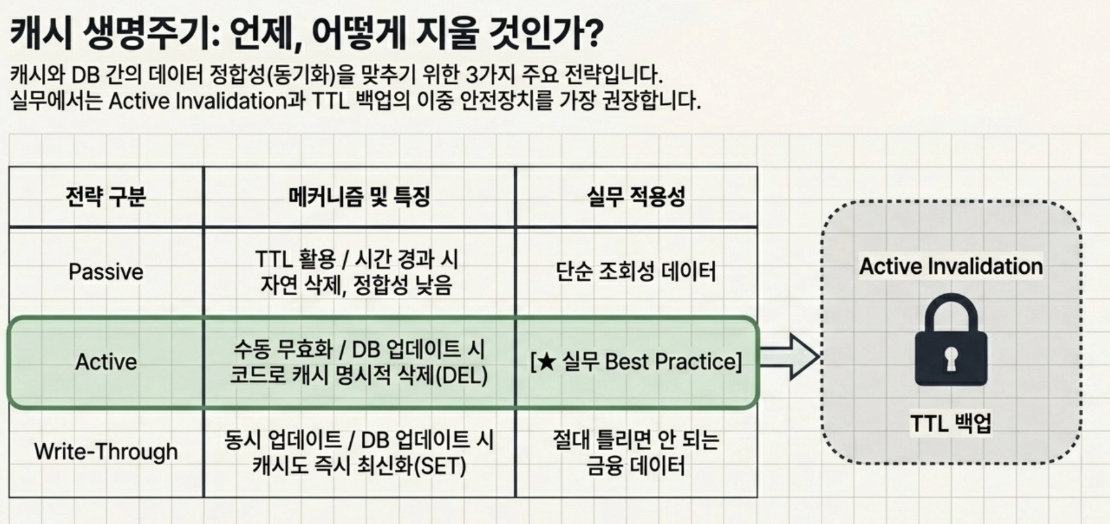
Passive Invalidation (TTL Utilization): The easiest way is to set the TTL and let it be erased over time.
Active Invalidation (manual invalidation): When an UPDATE or DELETE query occurs in the DB, the backend application code explicitly calls Redis’
DELcommand to blow the cache.Use of Write-Through: When updating the DB, there is also a way to set the contents of the Redis cache to the latest value as well.
→ In practice, Active Invalidation is mainly used as the default, but the double safety device that sets the TTL as a backup in case the deletion logic fails due to a system failure is most often used.
- What is the appropriate TTL (expiration time) setting?
Q If I cache the shopping mall’s ‘Terms of Use’ page and the ‘Bitcoin Real-time Price’ page, what should be the TTL for each?
- Since the terms and conditions do not change much, it should be long, and since the Bitcoin price keeps changing, it should be very short.
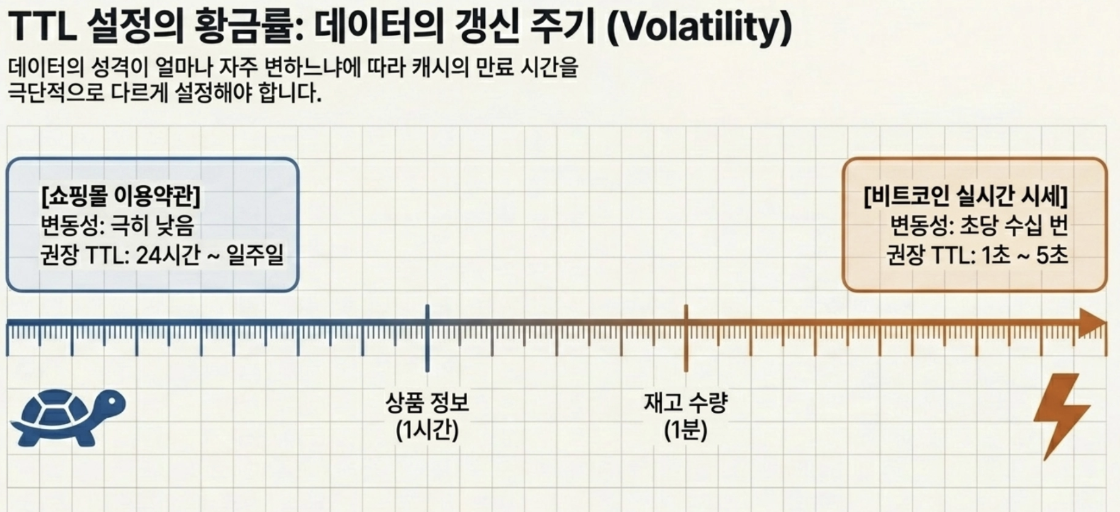
→ TTL must be taken differently depending on the data update cycle (volatility)
Cache Stampede Phenomenon - Deadly Trap
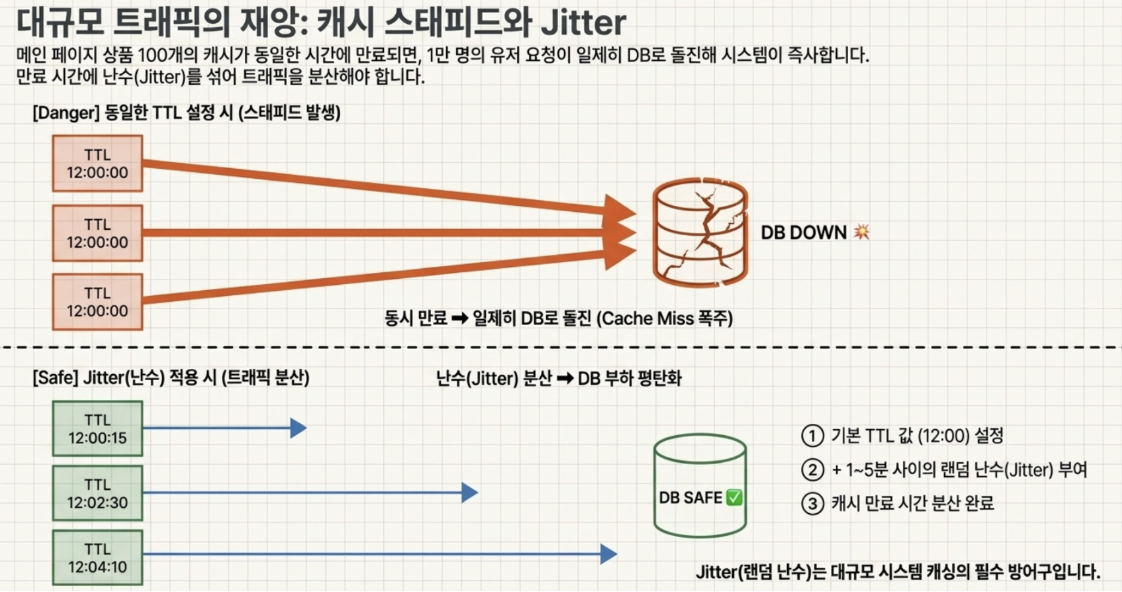
What would happen if the cache TTL of 100 products displayed on the main page were set to 12 PM sharp? - The moment 12 o’clock strikes, 100 caches disappear at the same time.
1
- At this time, if 10,000 users are connected per second, 10,000 requests rush into the DB with a cache miss at the same time → the DB goes down at that moment.
→ Therefore, in practice, when setting TTL for a large amount of data, a random number (Jitter) between 1 and 5 minutes must be added to the basic TTL value.
- This will distribute the cache expiration time and prevent the load from being concentrated on the DB at once.
Practical examples of 5 types of data structures
Assuming a popular shopping mall, we plan to map each data structure with commands.
- String
- Used to store simple text or counters
Q If you need to show ‘total number of visitors today’ on the shopping mall main page, what command should you use to implement it? → By using the atomic instruction
INCR, perfect counting is possible without concurrency problems.
List
Ordered data queue
Insertion/deletion at both ends is fast, but insertion in the middle is slow.
Example: Recently viewed product → Each time the user moves the page, the product is placed at the front of the list, and older items are cut out.
1 2 3 4 5 6 7
# 유저(999)가 상품(123)을 최근에 봤습니다. 리스트 맨 앞에 밀어 넣습니다. redis> LPUSH recent_views:user:999 item:123 (integer) 1 # 최근 본 상품은 딱 5개만 유지하도록 나머지는 잘라냅니다(Trim). redis> LTRIM recent_views:user:999 0 4 OK
Set
There is no order and no duplication is allowed.
Example: Event application on a first-come, first-served basis → When collecting event applicants who can only participate once per person, duplicates are blocked at the source.
1 2 3 4 5 6 7
# 이벤트(event_x)에 유저(999)가 응모했습니다. redis> SADD event_x:participants user:999 (integer) 1 # 유저(999)가 또 응모 버튼을 연타했지만, 중복이므로 무시됩니다. redis> SADD event_x:participants user:999 (integer) 0
- Pitfall to watch out for: When millions of data are accumulated, if you lose
SMEMBERS, which retrieves all items at once, the entire system stops → You must retrieve them separately asSSCAN.
- Pitfall to watch out for: When millions of data are accumulated, if you lose
Sorted Set (ZSET)- Core data structure that automatically sorts in score order by adding the concept of ‘Score’ to Set
Example: Real-time purchasing ranking → Real-time ranking is created using the user’s cumulative purchase amount as the score.
1 2 3
# 유저(999)가 50,000원어치 물건을 사서 랭킹 보드에 점수를 누적합니다. redis> ZINCRBY daily_ranking 50000 user:999 "50000"
Pitfall to be aware of: Score is stored as a Double → If you enter a large integer such as the maximum value of Java’s Long, a precision error may occur and the number may change, so be very careful.
Hash
Structure that allows multiple fields and values to be placed within one key
Example: Shopping cart → Store the product ID in a specific user’s shopping cart as a field and the quantity as the value.
1 2 3 4
# 유저(999)의 장바구니에 상품(123) 2개, 상품(456) 1개를 담습니다. # (Redis 4.0 이상에서는 HMSET 대신 HSET을 권장) redis> HSET cart:user:999 item:123 2 item:456 1 OK
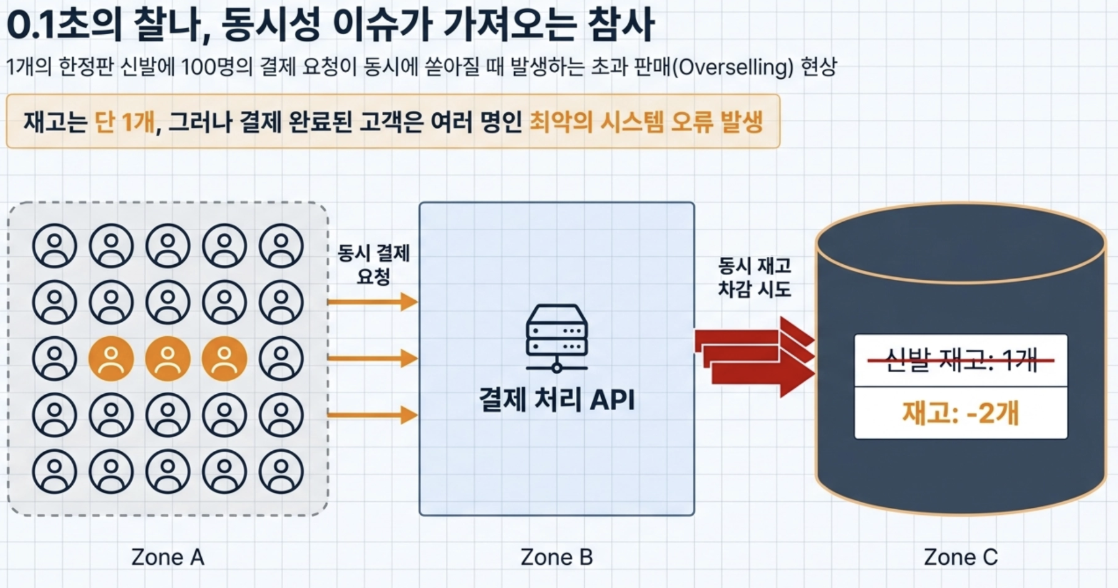
Practical example: Baedal Minjok B-Mart distributed lock
Q What happens if there is only 1 limited edition shoe left in a shopping mall, and 100 people press the payment button at the same time without an error of 0.1 second?
- There is only one item in stock, but the payment is processed at the same time, so it is sold to multiple people (overselling phenomenon)
→ The above phenomenon must be prevented by using a technology called Distributed Lock.
- WMS (warehouse management system) case of ‘B Mart’, a large domestic service delivery company
B Mart endlessly transfers product inventory from the central distribution center (DC) to the regional base center (PPC).
At this time, Manager A wants to allocate inventory to the base center, and Manager B can simultaneously make a request to ‘cancel’ this due to warehouse circumstances.
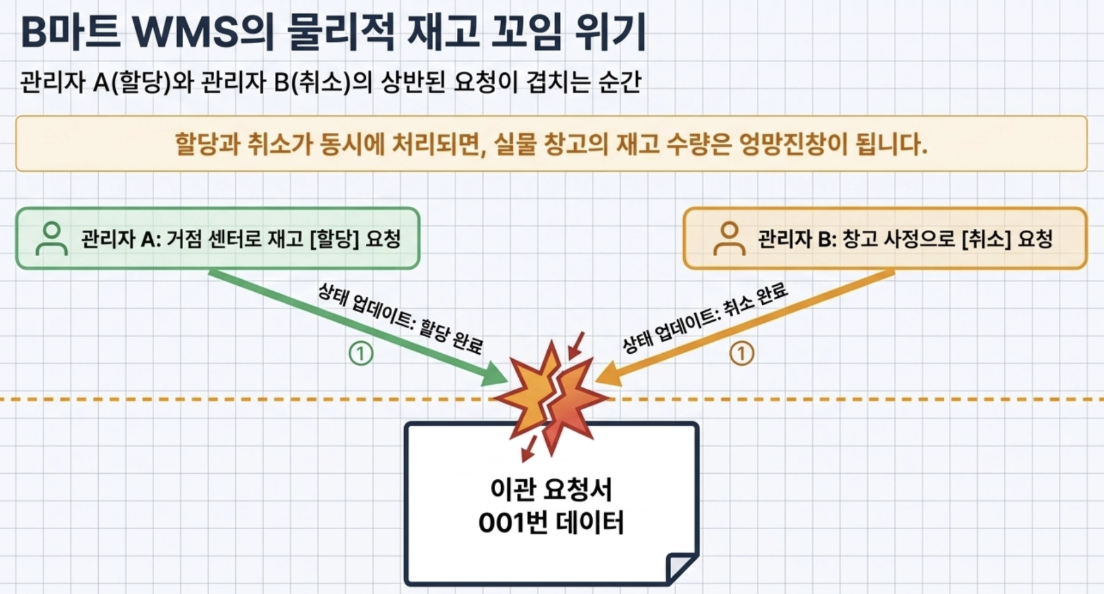
- At this time, if the system goes wrong and allocation and cancellation occur, the physical inventory quantity becomes a mess.
- Solution through Redis distributed lock
To prevent this problem, Baedal Minjok placed Redis distributed lock on a per ‘transfer request’ basis.
- If one server first obtains a lock from Redis for transfer request number 001, the other server is blocked from changing the status of the inventory until the lock is released.
- Through this, concurrency issues are completely controlled without even a single piece of data being distorted.
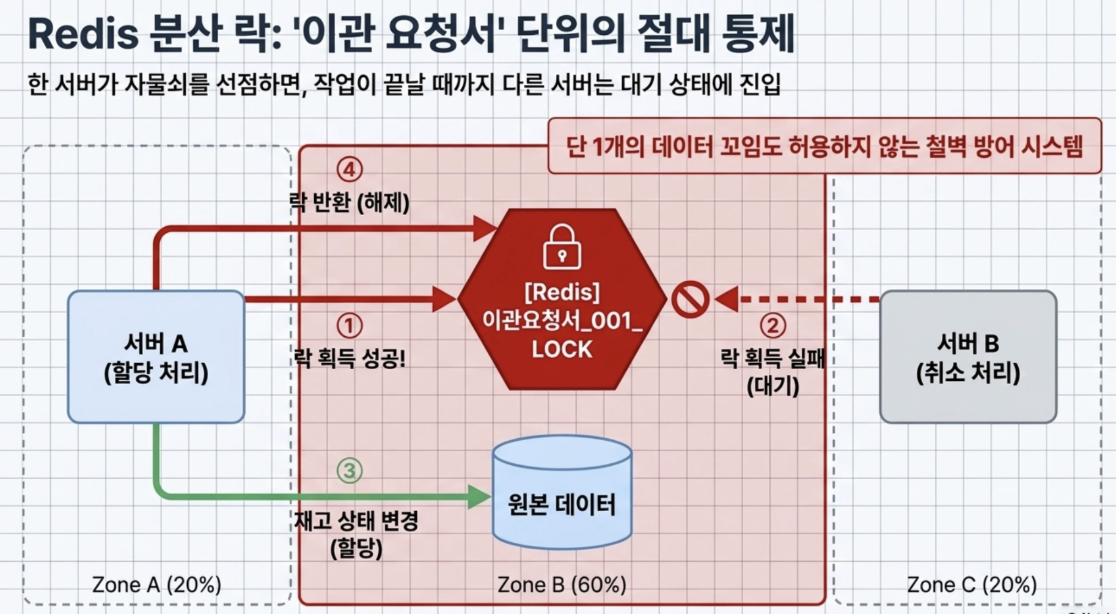
- Through this, concurrency issues are completely controlled without even a single piece of data being distorted.
What if there was no Redis?
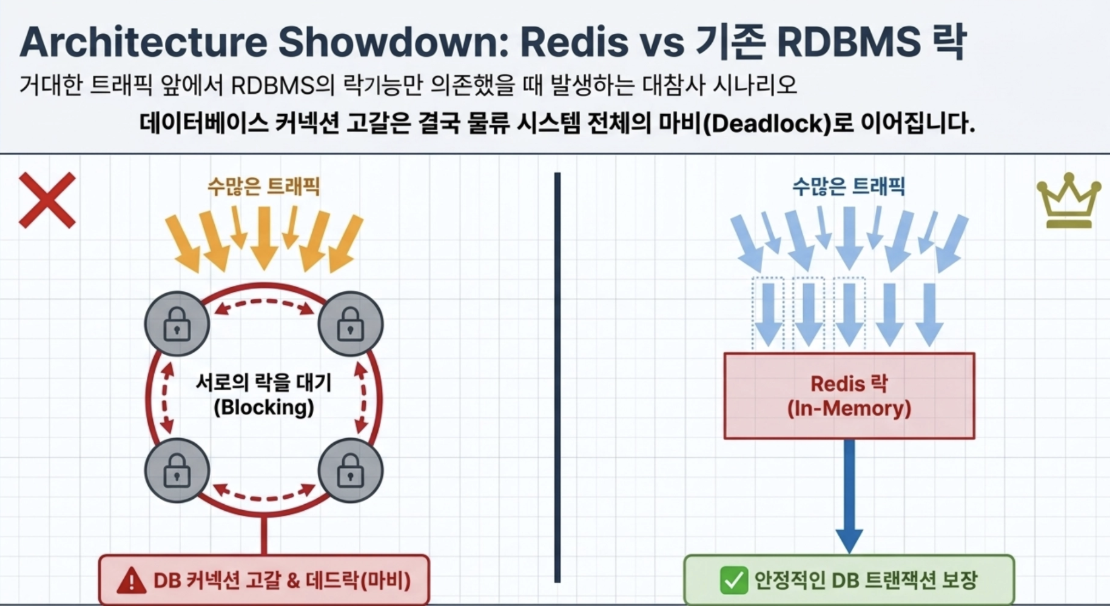
- If you were trying to handle inventory processing of this huge traffic only with the locking function of existing MySQL (RDBMS) without Redis’ distributed locking,
As numerous inventory allocation/cancellation requests poured into the DB, each other would have been clamoring to lock the row.
In the end, numerous queries would be in a blocking state, the DB connection pool would be depleted, and in the worst case, a catastrophe would have occurred in which the entire B-Mart logistics system would have been paralyzed due to deadlock in which each party was holding on to each other’s locks.
- If you were trying to handle inventory processing of this huge traffic only with the locking function of existing MySQL (RDBMS) without Redis’ distributed locking,
Finalizing Redis core architecture and basics
Redis uses memory to eliminate disk operations and completely guarantees atomicity without context switching delay through an event loop-based single thread.
You must set a TTL plus cache invalidation strategy and jitter according to traffic and requirements to prevent DB down due to Cache Stampede.
Beyond simple data storage, it acts as essential middleware for MSA architecture, such as distributed locks that solve concurrency problems in distributed systems.
Questions & Errors
Q I heard that existing disk-based DBs require locks and are slow because they are multi-threaded, but why does Redis use distributed locks since it is single-threaded?
- Redis’ single thread refers to Redis internally how commands are processed
In other words, because Redis processes only one command at a time in order, there are fewer conflicts that occur when multiple threads modify the same memory data at the same time.
Redis commands themselves are executed atomically.
- However, actual service logic usually consists of several steps.
Inventory inquiry
Check availability
Create order
Reduce inventory
→ As a result, there may be more orders than inventory.
To prevent this problem, use Distributed Lock- Distributed locks play a role in limiting “only one server can perform this task now.”
1 2 3 4 5 6 7 8 9
```plaintext 서버 A: 락 획득 성공 서버 B: 락 획득 실패 → 대기 서버 A: - 재고 확인 - 주문 생성 - 재고 감소 작업 완료 후 락 반납 ```
Key Differences
concept meaning Redis single-threaded Redis internal command processing method DB lock Prevent DB internal transaction conflicts Redis distributed locking Control concurrent operations across multiple servers/requests